In March 2022, Tarides made further strides improving the storage I/O performance, which will be available with the upcoming Octez v13 release. Our work on improving the Irmin performance resulted in Tezos reaching 1000 TPS! With the release of Irmin 3 and Octez v13, transactions have become 5x faster than they were with Octez v12 (6x compared to Octez v10). Additionally, we’ve further stabilised the storage layer and reduced the memory required by 80%. This is a great improvement for all the Tezos users (and especially bakers), as it will make the network more stable and the baking rewards much more predictable.
In March, we also continued to develop and optimise the Merkle proofs feature of Irmin, which the upcoming Transaction Rollups project will use. We introduced Merkle proofs in the upcoming Jakarta proposal as partial, compressed Merkle trees to streamline data integrity verification.
Keep your eye on the Tarides blog for upcoming blog posts on these topics. Also, if you’re new to Irmin, the storage component used by Octez, please read more on our website Irmin.org.
Improve the Performance
Improve Tezos Storage I/O Performance
We’ve been improving the irmin-pack I/O performance, the Irmin backend used in the Tezos storage layer. irmin-pack writes data in an append-only file called a pack file, so in order to efficiently retrieve the data, irmin-pack uses Irmin’s Index library, which maps hashes of objects to their location in the pack file. In order to optimise performance, we implemented the structured keys feature, adding structural information in the keys to avoid accessing the Index for every read. We’ve provided two indexing strategies for the structured keys:
- The
minimal indexingstrategy drastically reduces the numbers of I/O syscalls resulting in doubling the TPS. - The
always indexingstrategy keeps the structure flat to preserve the initial indexing format where all objects (commits, nodes, and contents) are added to theIndex.
Overall, the structured keys unburden indexing the pack file at the cost of some potential duplication of objects on disk. With the upcoming release of Octez v13, we will reach our performance goal of supporting one thousand transactions per second (TPS) in the storage layer! This is a 6x improvement over Octez 10. Even better, this release also makes the storage layer orders of magnitude more stable with a 12x improvement in the mean latency of operations. At the same time, we reduced the memory usage by 80%. Now Octez requires a mere 400 MB of RAM to bootstrap nodes! More details on this soon.
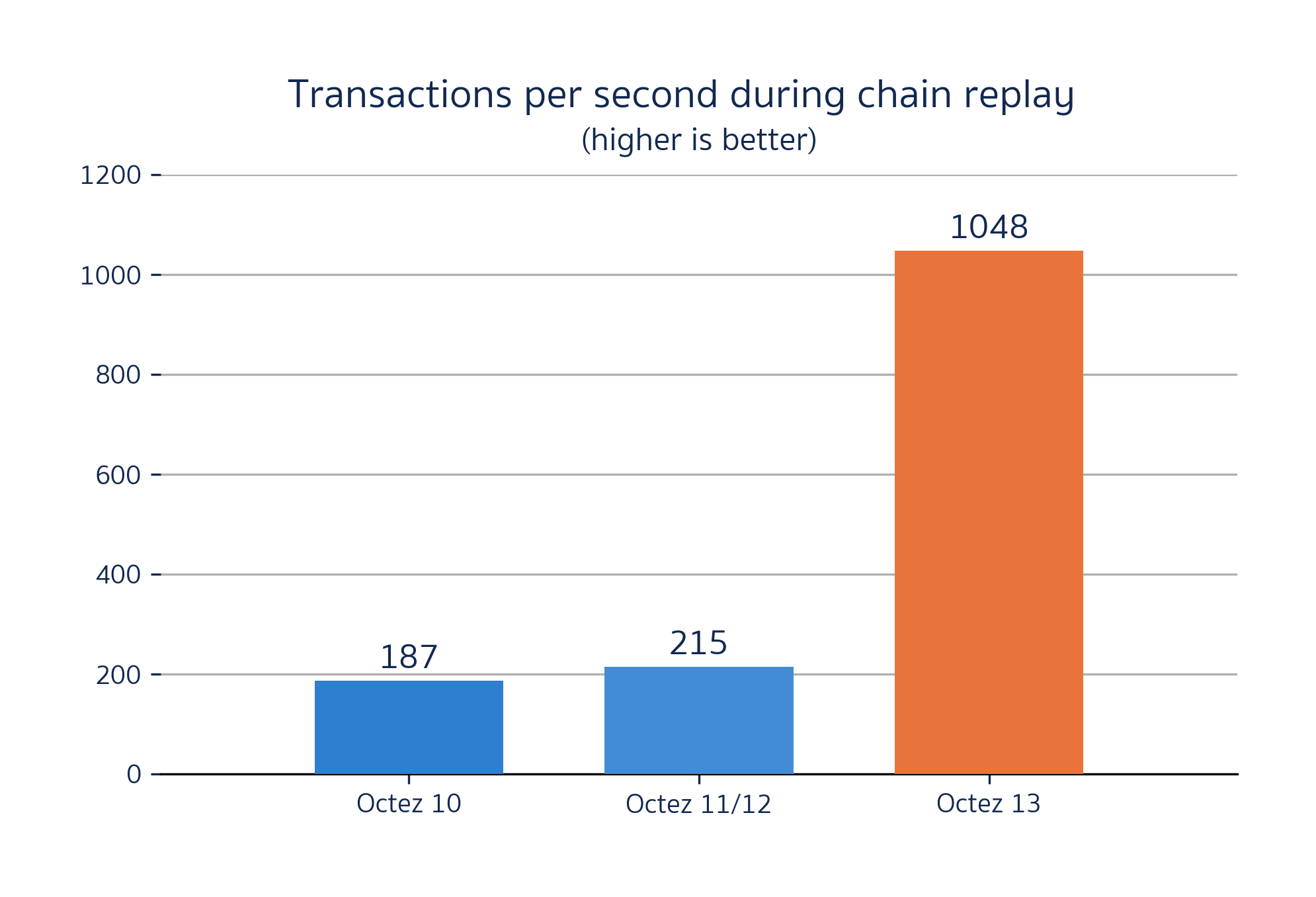
Comparison of the Transactions Per Second (TPS) performance between Octez 10, 11, 12, and 13 while replaying the 150k first blocks of the Hangzhou Protocol on Tezos Mainnet. Octez 13 reaches 1043 TPS on average which is a 6x improvement over Octez 10.
Status: This work is complete and will be included in Octez v13. In preparation for the release, we’ll publish a blog post documenting the structured keys when the rc1 release will be announced.
Publish Irmin/Tezos Performance Benchmarks
Additionally, we continued to automate the benchmarking system that runs monthly and publishes benchmarks regularly in order to keep Tezos developers informed of Irmin’s performance. As part of this work, we developed Equinoxe, a library to programmatically deploy equinix machines. This month we introduced a tag system in Equinoxe, and we are working on a “safe” mechanism to check the availability of machines.
In order to ensure that benchmarks are reproducible, we created an opam lock file with the exact dependencies of the benchmarks for each month. A Python script uses opam-monorepo to install everything, then runs the benchmarks, converts the results into JSON files, and transfers them to a remote server that stores all the results. We generated lock files for every month last year and stored them at tezos-storage-bench. In the future, we want to maintain lock files on irmin#main. To do this, we needed to make opam-monorepo work for Irmin, as well as port some libraries to Dune (mtime, rresult, ocaml-git). A draft PR on Irmin adds the lock file; however, we need to wait for the opam-monorepo release in order to move to Dune 3.0 and fix the MDX stanza.
Status: Automating the benchmark system is a rolling work because we ameliorate the system as we go.
Relevant links: tezos-storage-bench#2, equinoxe#76.
Record/Replay of the Tezos Bootstrap Trace
We are working on a benchmarking system to integrate into Octez’s lib_context. Running benchmarks from Octez directly is important to ensure there isn’t regression in either Irmin or lib_context, but also it allows Tezos developers to reproduce them or benchmark Octez with a different storage backend.
In March, we integrated snapshot import and export in the benchmarks.
As we transition to a new system, we must maintain two sets of benchmarks: the “old” benchmarks running in Irmin, and the new ones in tezos/lib_context. We backported the new benchmark system to older versions of Octez (v11, v10, v09) and worked on scripts to run all our benchmarks in a reproducible way.
Status: We plan to publish these benchmarks in an upcoming blog post where we compare Octez v13/Irmin 3.0 with previous versions of Octez. We also compare different indexing strategies used in Irmin 3.0.
Relevant liks: tezos-storage-bench#7, tezos#v11-trace-record.
Continuous Benchmarking Infrastructure
We are maintaining a continuous benchmarking (CB) infrastructure, that runs on every PR on Irmin and on Irmin-related repositories. We are adding new features to the CB to increase its usability. For instance, when the CB fails, one had to check the status of a PR to see it. Now the CB sends logs to slack to warn of production failures. We also added the option to run benchmarks on a different schedule than “as soon as a PR changes”.
The monthly Irmin benchmarks must push their results via the HTTP API, so we added a small client library to ease its usage.
Status: Automating the benchmark system is a rolling work because we ameliorate the system as we go.
Relevant links: current-bench#327.
Improve Snapshot Import/Export
After the activation of Hangzhou, the memory usage during snapshot import/export increased significantly, reaching 8GB, because the very large context directories (containing a few million entries) are loaded in memory during snapshot import/export.
On April 7th, we released Irmin 3.2, which contains the improvements to the snapshot. We exposed the internal nodes Irmin uses to represent these large directories in an optimised way. It considerably reduces the memory usage of the import and export. In our benchmarks during import, maxrss goes from 7.5GB to 1.6GB while improving the total time as well.
Although this requires a change to the snapshot format, the import will be backward compatible; however, the export will only use this new format.
Status: This work is complete and will be included in Octez v13.
Relevant links: tezos#2312, irmin#1757, tezos#4860, tezos#4862.
Add Monitoring for Irmin Stats to a Tezos Node
Tezos nodes can run with a Prometheus server attached to monitor and report node execution stats. The node launches the Prometheus server, now integrated into the Tezos codebase, when requested by users. We plan to add Irmin-specific stats to this monitoring system so that users can inspect them while running a Prometheus server.
We started investigating different monitoring systems used in Irmin (the mirage/metrics and mirage/prometheus libraries), as well as the metrics used by the Tezedge node.
Status: Scheduled for Q2
Add Merkle Proofs
Since Merkle proofs are used to efficiently and securely encode blockchain data and to give authenticity and integrity guarantees for partial transaction states shared between parties, Tarides focused on optimising Merkle proofs to save bandwidth when requesting transaction data.
The Rollups project now uses the Merkle proof API exposed by Irmin, which will be part of the Jakarta protocol proposal. In collaboration with NL, we fixed some details in the API, so the errors returned by proof verifiers are now more informative.
Status: We added an example of using Irmin’s API, on which we’ll publish a blog post in April.
Relevant links: irmin#1791, irmin#1802.
Improve the Space Usage
Integration of Layered Store/GC
The layered store feature consists of organizing the context of a Tezos node in two layers:
- A read-write layer that contains the latest cycles of the blockchain, which can still be reorganised and are not final
- A read-only layer containing older data that’s frozen
The layered store feature comes with a GC operation, which periodically discards the oldest cycles and keeps only the recently used data on disk. The GC operation is performed asynchronously with minimal impact on the Tezos node. The advantages of a layered store for the rolling nodes include using less disk space and maintaining constant performance throughout the run of a node, without needing a snapshot export and import when the disk’s context size gets too big. For archive nodes, the benefit is also better performance while bootstrapping, as only the read-write layer is needed for validating recent blocks.
In March, we continued to work on that feature. We fixed some bugs related to how the layered store will interfere with caching in Irmin. Also, we investigated how to get a fork for Lwt that matches our use case. For now, we call another executable to compute the reachability of a commit, needed by the GC. We have a working prototype of the layered store, and we are testing its integration in Tezos. We also benchmarked for the beginning of the bootstrap, and the results are very promising.
Status: We plan to have the layered store in Tezos in Q2.
Relevant links: BR_layered; BR-layers-rebased, BR-worker-cached-constructors, lwt-discussion.
Maintain Tezos’ MirageOS Dependencies (TA)
General Irmin Maintenance
We fixed several CI failures in March. We also added a configuration option to irmin-pack stores that prevent adding empty trees. We refactored the tests for irmin-graphql to simplify the way queries are written and the results are parsed in order to reduce the boilerplate when writing future tests, and we added documentation.
Status: Rolling.
Relevant links: irmin#1750,irmin#1787, irmin#1789, irmin#1794, irmin#1796, irmin#1799, irmin-query, irmin-tezos#34, irmin-tezos/#35, GraphQL-docs.
Provide Tezos Support
Respond to and Track Issues Reported by Tezos Maintainers
Some nodes running on Hanghzhounet are failing with an “inconsistent hash” error. We investigated the corrupted store and ran an index integrity check, but it didn’t reveal any issues. We managed to reproduce the error by bootstrapping a node with Hanghzhounet and closing it just before the problematic block. When restarted, the node failed with the same error.
Status: We are continuing our investigation into this in April.
Relevant links: irmin#1797.
Improve Tezos Interoperability
Rust and Python Bindings for Irmin
The C bindings for Irmin are now part of the Irmin repo. The Python and Rust bindings have been released and are available as irmin-py and irmin-rs, respectively. This allows for the integration of Irmin in protocols that use Python and Rust as a development environment. As such, we make Irmin versatile and available in other development environments used by Tezos.
The Irmin bindings are close to being wrapped up. In March, we added more tests and more documentation. We experimented with tracking allocations done by libirmin in order to check for memory leaks in irmin-rs and irmin-py, but it requires more work to be properly integrated. Moreover, we have started investigating how to integrate Irmin bindings into Tezedge.
Status: The Irmin bindings are available (see relevant links) and ready to be experimented with.
Relevant links: irmin-py, irmin-rs.
Tezos & Irmin in the Browser
The internship project started in February consists in combining irmin-indexeddb and irmin-server to produce an offline-first application with fast and efficient synchronisation. Offline-first applications ensure that apps work just as well offline as they do online. Thanks to Irmin’s mergeable replicated data-types, it becomes much easier to build applications that can transform the state offline and resynchronise the state later. For Tezos, this could be useful to write web applications to interact with the context state directly.
Our short term goal is to build a simple mini-github project to display details of a Git repository as a sample project on how to combine irmin-graphql + dream on the server side and jsoo + dream for the client. We have launched server queries for Git repository data stored and accessed through irmin-graphql, and we’ve managed to get the Irmin store to synch properly. We have also worked on the UI part of the project by investigating websockets and the websocket-async library for the browser communication with the irmin-server.
Status: The offline-first Irmin application is scheduled to be available by the end of Q2 2022.
Relevant links: simple_mini_github#1, simple_mini_github#2, simple_mini_github#3, simple_mini_github#5, ocaml-git#561.



