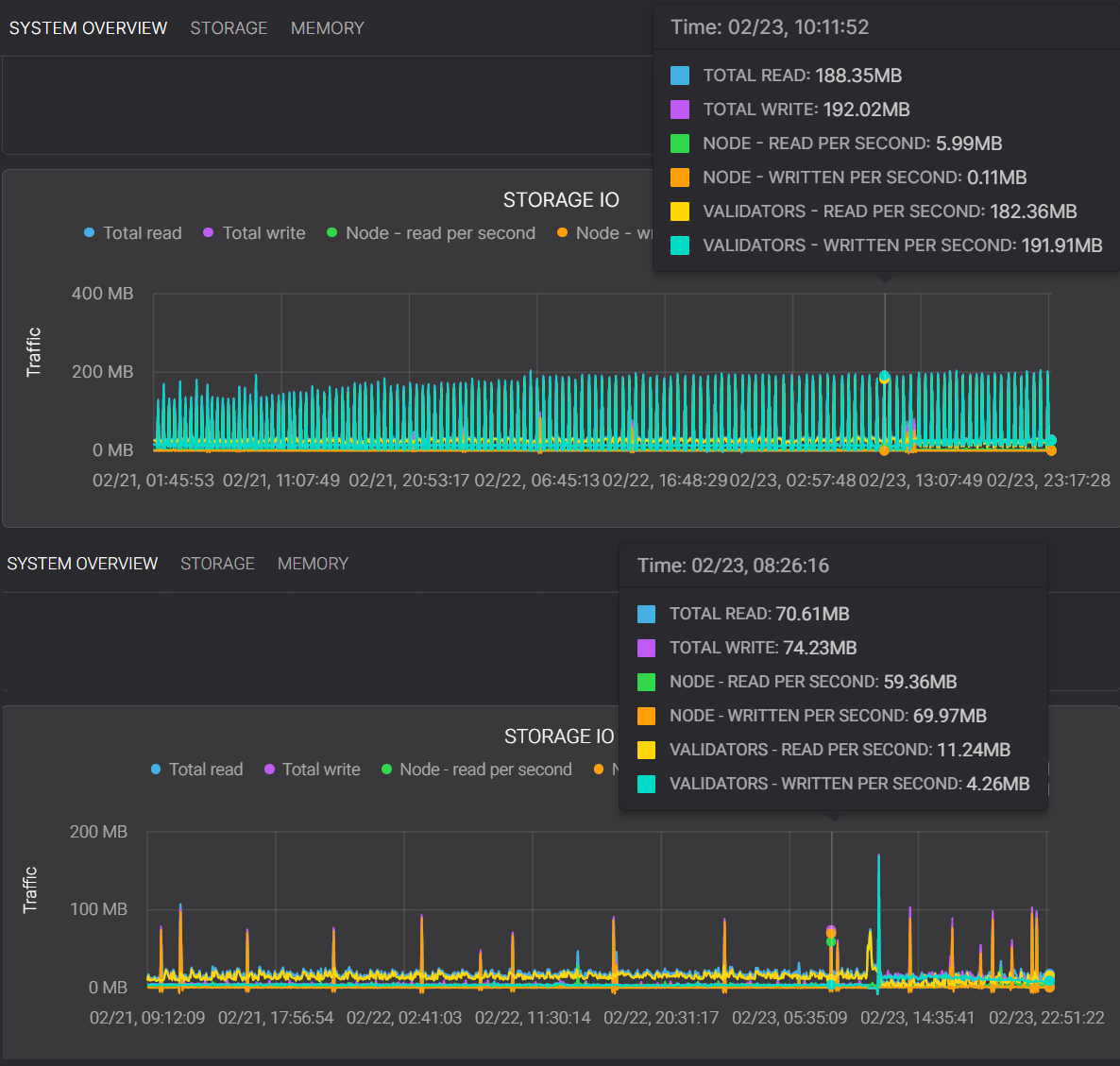
I/O graph comparison of the Octez v11 context storage (upper) and the TezEdge v1.15 context storage (lower). Notice the improvement in reads and writes per second, as well as the lack of spikes in performance.
Improving the storage is one of the most effective ways of improving a blockchain node’s overall performance. Blockchain nodes must regularly and continuously access the storage that contains the blockchain state (also known in Tezos as the context). The speed at which a node can access this storage affects block application time — a slower storage module will slow down block application, thus constituting a bottleneck for the overall speed and stability of the node.
If the storage is not available for some reason, then the application of blocks cannot proceed and the node ‘freezes’. When such freezes happen (which can last many minutes), the node gets stuck until the storage has finished performing its maintenance tasks. If block application takes more than 30 seconds (the time currently allowed for block creation, also known as the block time), then the baker might not be able to bake the block and they can lose their reward for baking or endorsing.
A faster, more reliable storage for better baking
Until now TezEdge supported two different implementations of the context storage, the Octez v11 implementation, and our own Rust-based implementation of a garbage-collected in-memory storage that only keeps the data from the latest 7 cycles.
Now there is a third option. We’ve developed a persisted context storage that saves the entire Tezos blockchain state on-disk and we have named it the TezEdge v1.15 context storage. This has translated into a major improvement in performance when compared to the Octez v11 implementation:
- The TezEdge v1.15 context storage performs a little over half as much reads (input) and less than a third of writes (outputs) into the disk compared to the Octez v11 implementation. It also has minimum variance, meaning that there are no spikes in reads/writes. You can jump to the section titled Advanced tracing tool for context storage to see the full details.
- Additionally, our implementation does not suffer from the aforementioned freezes. This increases the probability of being able to successfully bake or endorse a block and obtain the reward.
The next version of Octez (v13) will feature an improved storage implementation that addresses the issues we have discussed in this article. We are looking forward to working the team behind Octez to publish an updated version of our benchmarks once it is released.
Measuring the performance of the two storage implementations
If we want to perform any kind of work with a Tezos node, we need to first bootstrap it, meaning that we need to re-process every block of operations, starting with the genesis block and finishing with the block at the head of the chain.
We launched two instances of the TezEdge node while using 16GB of RAM and allowing a maximum storage bandwidth of 300MB/s for both. The only difference between the two instances was that one used our new and improved TezEdge v1.15 storage, while the other used the Octez v11 storage.
Bootstrapping a node is limited by two constraints: the Tezos economic protocol and the storage of the node that is being bootstrapped. The TezEdge v1.15 storage required 44,131 seconds to complete the processing of over 2 million blocks (95.1% bootstrapped). Meanwhile, the Octez v11 storage needed 295,756 seconds to perform just 75.4% of the storage part of the bootstrapping (1.6 million)
Octez v11 storage statistics
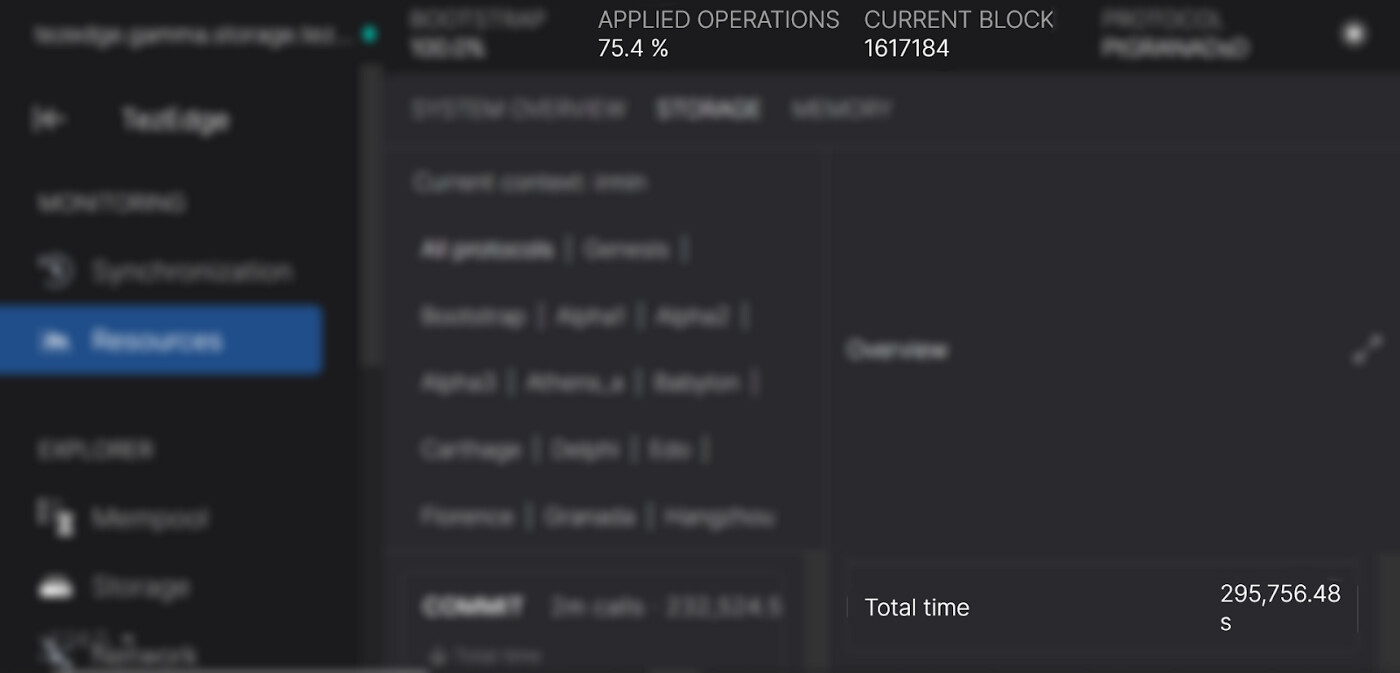
http://irmin-ram-16gb-io-300mb.storage.tezedge.com/#/resources/storage
TezEdge v1.15 storage statistics
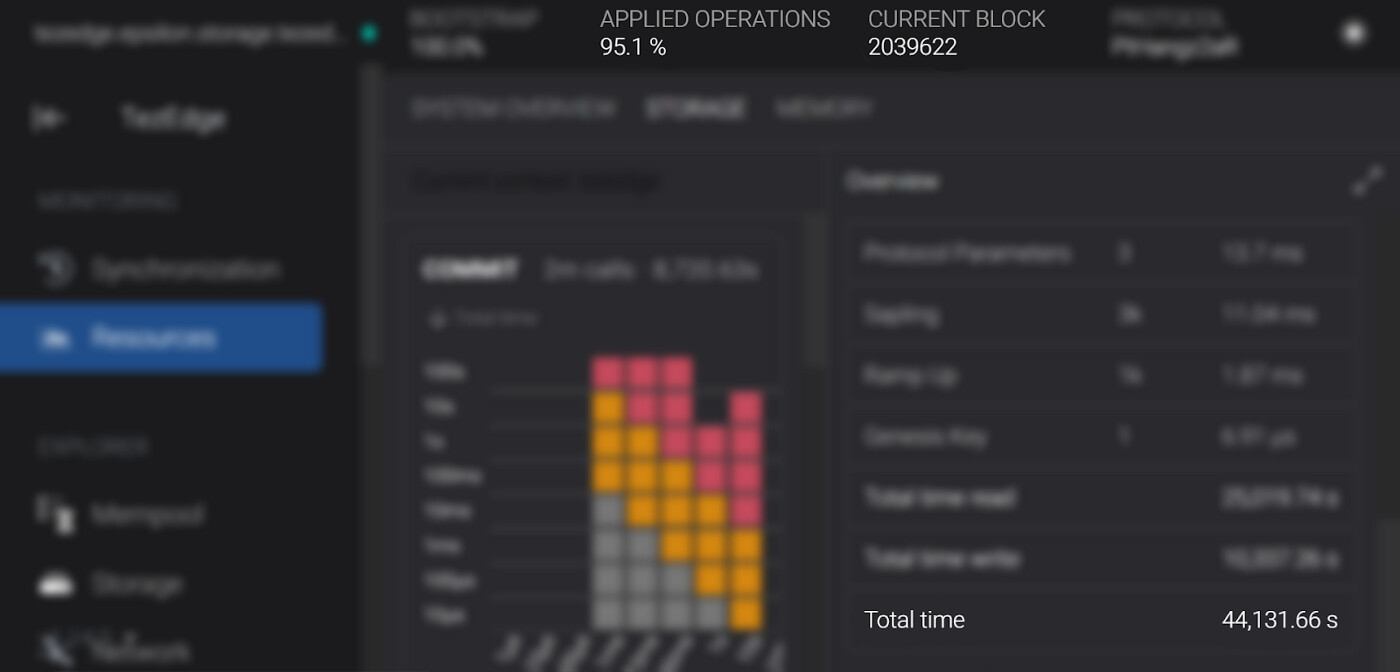
http://rust-ram-16gb-io-300mb.storage.tezedge.com/#/resources/storage
On the right side of the STORAGE tab you can find the full statistics. Scroll down to the bottom to find the total time, which is the important value here. It is much less in the new TezEdge v1.15 storage, mostly thanks due to its avoidance of freezes. Additionally, one of the reasons the Octez v11 storage implementation spends so much on reads is that it also needs to wait for merges
Since our project is developing a Tezos node shell, our focus is on every module that is a part of it. This includes the storage, and optimizing it greatly affects the speed of bootstrapping. The reason why our storage performs so well is that we not only reduced the size of the data necessary for bootstrapping, but we also sped up the rate at which it is processed.
Improving storage performance by index trimming and direct addressing
In the TezEdge v1.15 context storage, our data files are append-only, meaning new data can be appended to the storage, but existing data is immutable. Ordinarily, finding values within an unordered data file is done via a linear scan (sequentially checking each value in the list until a match is found or the whole list has been searched). However, such scans tend to be quite expensive for large datasets. Databases usually avoid that by using indexes.
Database indexes are special lookup tables consisting of two columns. The first column is the search key, and the second one is the data pointer. The keys are the values you want to search and retrieve from your database table, and the pointer or reference stores the disk block address in the database for that specific search key. The key fields are sorted so that it accelerates the data retrieval operation for all your queries.
These indexes often are just a sequence of ordered entries, but new entries are added in random order. This means that from time to time, you need to sort the index. This type of maintenance work takes some time, and in some cases, will leave the storage unavailable until it is complete.
In the current Octez v11 context storage (Irmin 2.9 for Octez v11) , there is an index that can be used to address any stored object by its hash. This index can grow very big (larger than 70GB for a node containing all the mainnet history right now), which makes its maintenance very costly.
The indexes we use in the TezEdge v1.15 only store references to the commits special objects in the storage that contain information about specific versions of the Merkle tree that represents the blockchain state, making them much smaller. They are small enough to be completely loaded and sorted in-memory when the node starts — for instance, the commit index, which is our main one, has less than 100 MB. Such small indexes do not require regular maintenance — the on-disk indexes do not have to be sorted. For this reason, the TezEdge v1.15 storage is not susceptible to freezes. Additionally, storing the indexes in-memory improves performance.
This works because in Tezos, the storage objects are never addressed directly, but instead are reached by traversing a Merkle tree that begins at the commit object. In addition to this, objects in the tree always reference other objects by their offsets in the database file, not by their hash. This avoids one costly indirection when trying to find objects in the store.
The next version of the Octez context storage (Irmin 3.0) will also implement a solution to the big indexes problem similar to what we described here.
Tracing and preventing high latency calls that threaten baking rewards by reducing latencies in the context storage
Since blocks in Tezos have to be baked within 30 seconds, bakers may lose out on the baking or endorsement reward if a call (such as a commit) takes too much time. This tends to happen when the storage suffers from the spikes we discussed earlier in the article.
This is why our primary goal is to reduce the latency of calls — so that no individual call causes bakers to lose their reward by taking too much time. Our secondary goal is to reduce the total time these calls take so that the node’s storage performs better.
We’ve developed an advanced tracing tool for calls made in the storage. We can use this tool to compare storage implementations and we can even select any past or current protocol.
Advanced tracing tool for context storage
To check out the tracing tool, go to this link:
https://tezedge.com/#/resources/storage
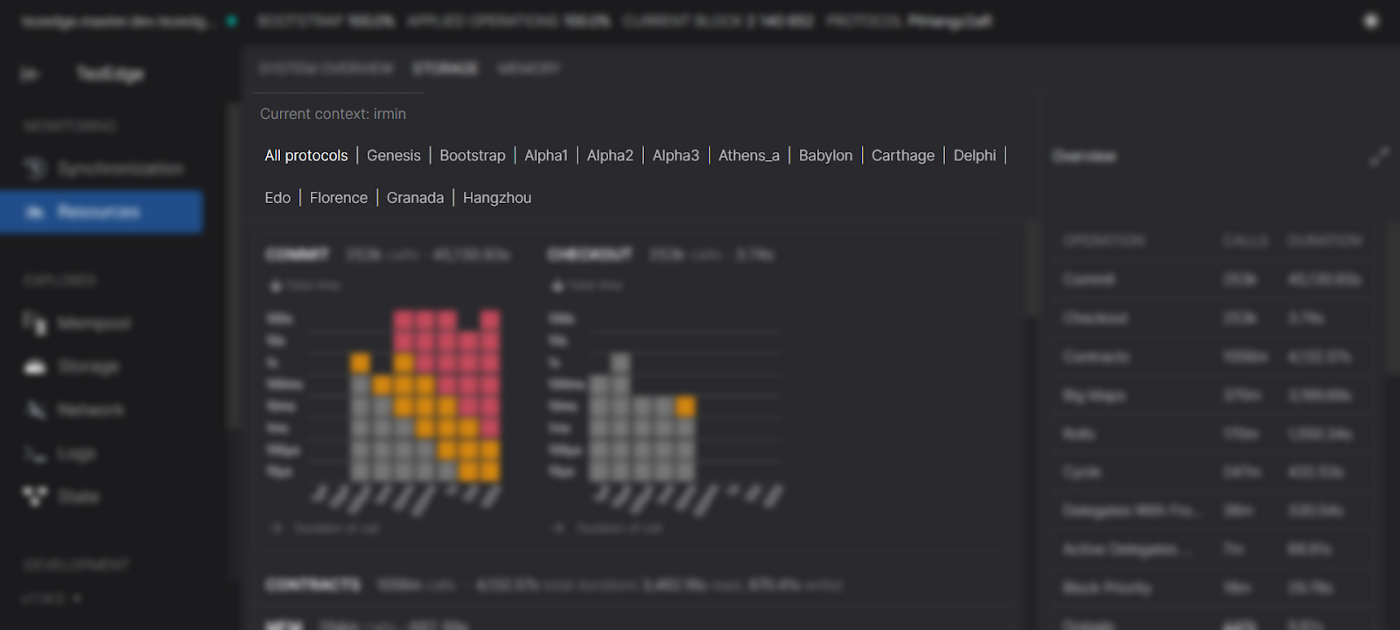
From the top downwards, underneath the highlighted STORAGE tab, you can first see that the Current context is irmin, meaning that the statistics displayed are for the Octez v11 context storage.
Underneath that is a list of all Tezos protocols. Let’s select Hangzhou, the latest protocol, because that is what bakers are currently using.
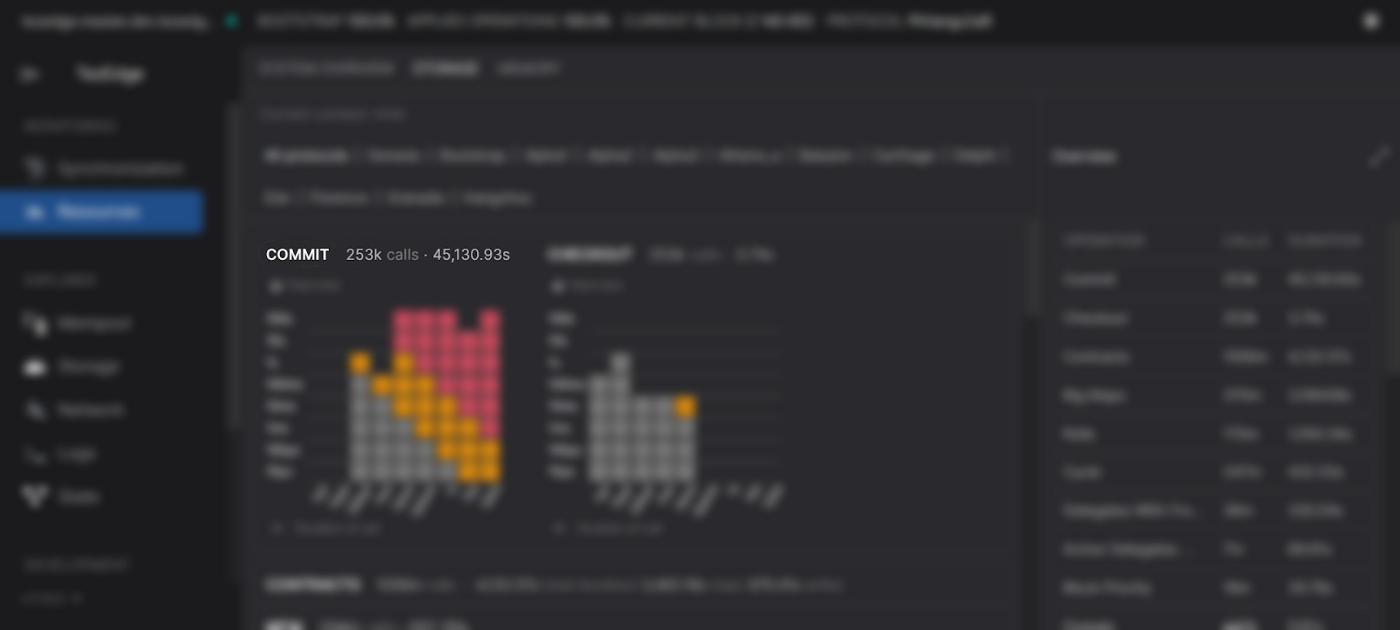
From left to right, first, we see the name for the type of action, this graph is for all COMMIT calls.
Then we see the total number of COMMIT calls made, which is 253k (253,000).
The total time of all these calls is 45,130.93 seconds.
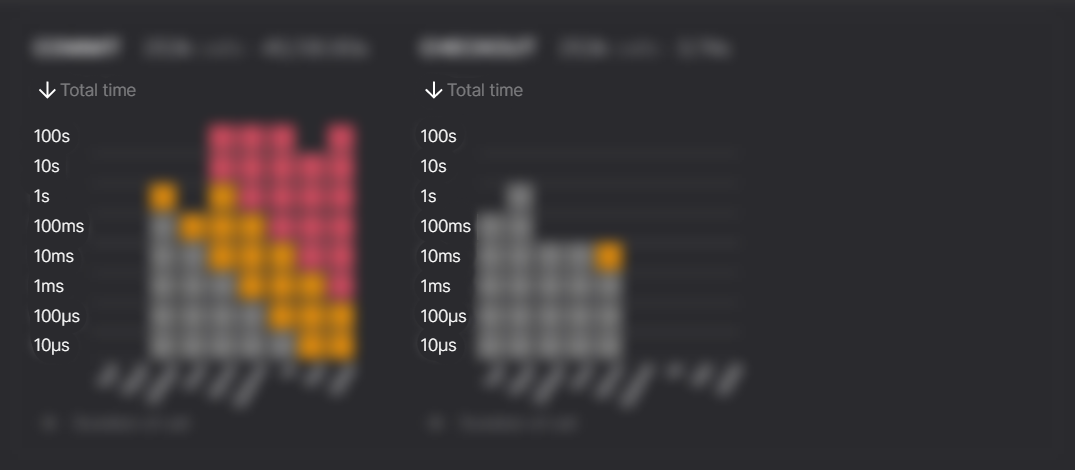
The y axis represents the total time of all COMMIT calls.
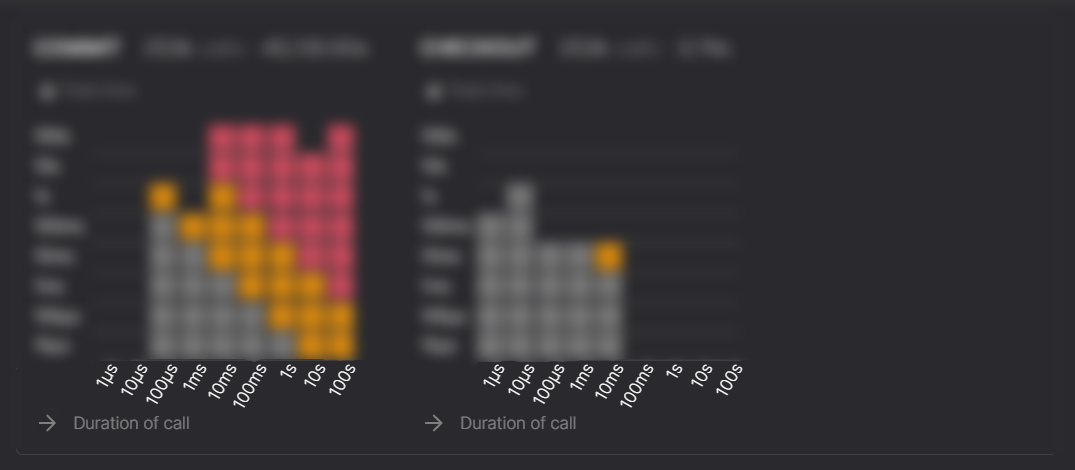
The x axis represents the duration of COMMIT actions
The graph is organized into vertical rows of blocks. Each vertical row represents calls made within a specific range of time as described in the x axis titled Duration of call.

Hovering the cursor above a vertical row displays a tooltip that shows:
- How many calls were made within that range
- Their mean (average) duration
- Their maximum duration
- The total time of these calls
The grey squares denote that the calls have an adequate duration. Orange squares denote durations that are longer than usual, and red squares denote that the duration is too long and will pose a risk to baking rewards.
Large call latencies may lead to lost baking and endorsement rewards
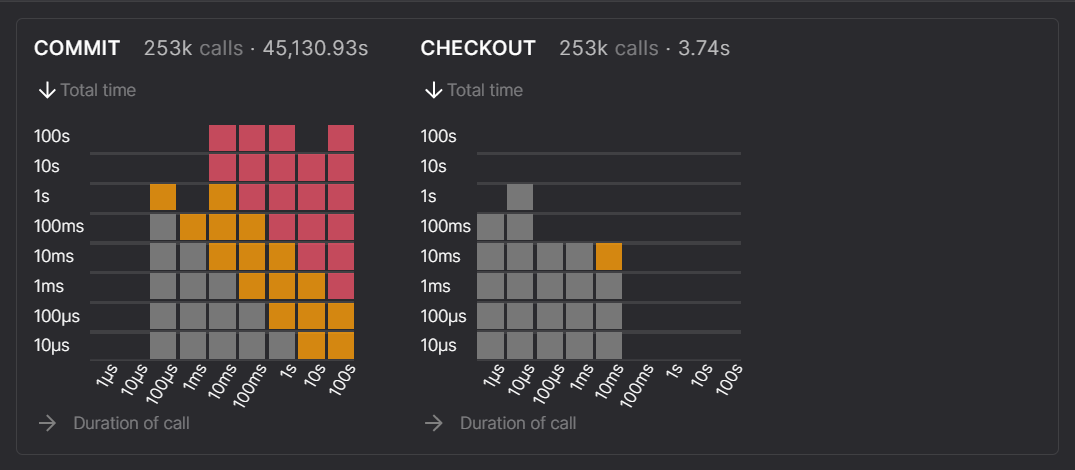
In this screenshot, we can see that there are 82 calls that are in the >100 second range. Since block creation has a 30 second constraint, such a large number of >100s calls will prevent blocks from being applied, which means baking and endorsement rewards will be lost.
Prolonging SSD lifespan for node owners by reducing storage I/O
As described previously, we have not only significantly sped up the rate at which the data is read and written, but we have also reduced the amount of data that has to be read from or written into the node’s hard disk.
Reducing the amount of data that has to be written and read is particularly valuable for major baking services who use enterprise-level SSDs in the servers on which they run their nodes.
SSDs have a limited lifespan that is further shortened by storing data onto them, with the reduction in lifespan being proportionate to the volume of data stored. Therefore reducing the amount of data that has to be written onto the hard disks used in baking allows them to last longer.
This will become even more important in the future as the size of blockchain data and the requirements for storage will exponentially grow.
Performance benchmark
We’ve launched two instances of the TezEdge node, one using the Octez v11 storage implementation while the other uses the new TezEdge v1.15 context storage. You can view each instance via the in-browser TezEdge explorer:
For the Octez v11 storage implementation storage context, go to this link:
http://irmin-ram-16gb-io-300mb.storage.tezedge.com/#/resources/system
For the new and improved TezEdge v1.15 persisted storage context, go to this link:
http://rust-ram-16gb-io-300mb.storage.tezedge.com/#/resources/system
Please note that at the time this article was written:
- The node running with the the Octez v11 context storage used by Octez has processed 1620147 blocks and has applied 75.4% of operations.
- The node running with the TezEdge v1.15 context storage has processed 2039622 blocks and applied 95.1% of operations
Although the system overview tab begins with a graph for CPU and then RAM, in this article, we begin with a comparison of STORAGE I/O, because this is the most important graph in terms of the storage’s overall performance, and how much it affects successful baking and endorsing.
I/O spikes can slow block application and threaten baking rewards
Octez v11 Storage I/O

TezEdge v1.15 Storage I/O
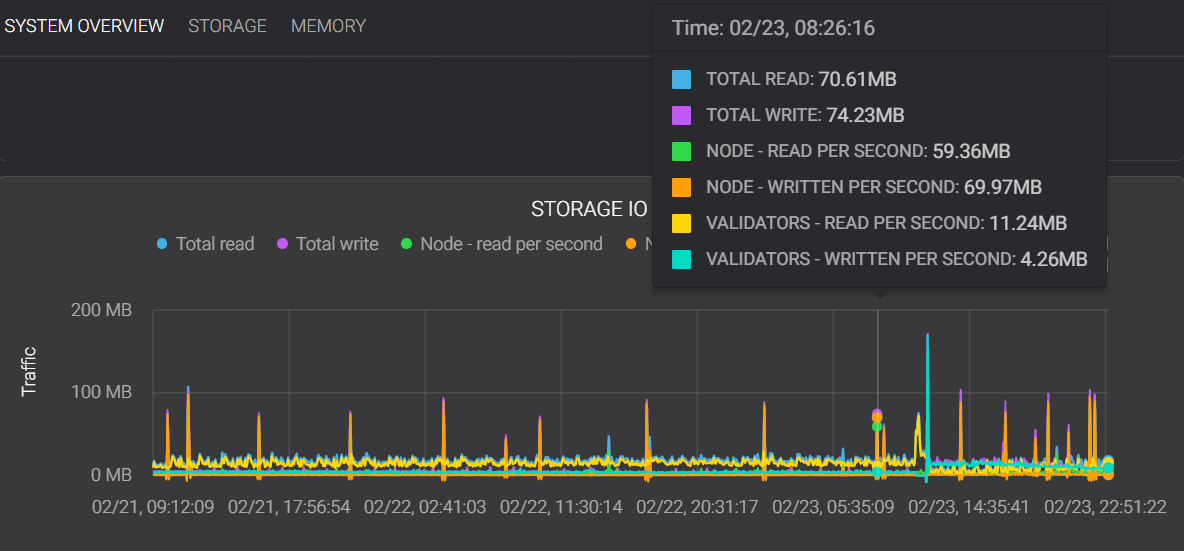
Please note that here the cursor is intentionally placed on a spike in both graphs. Additionally, the y axis of the Octez v11 storage chart stops at 400MB while the TezEdge v1.15 storage stops at 200MB.
The input/output of the TezEdge v1.15 storage is significantly lower than that of the old version of the storage. The important values here are:
-
Validators — read per second, which in the TezEdge v1.15 storage is a bit more than half of what it is in the Octez v11 storage, and -
Validators — written per second, which is less than a third of what it is in the Octez v11 storage.
While there are a few spikes, they are much less frequent and they never reach the same heights as those in the graph from the Octez v11 storage. The cause of such spikes in Octez v11 storage implementation is the merging of the index, which grows bigger as more blocks are processed.
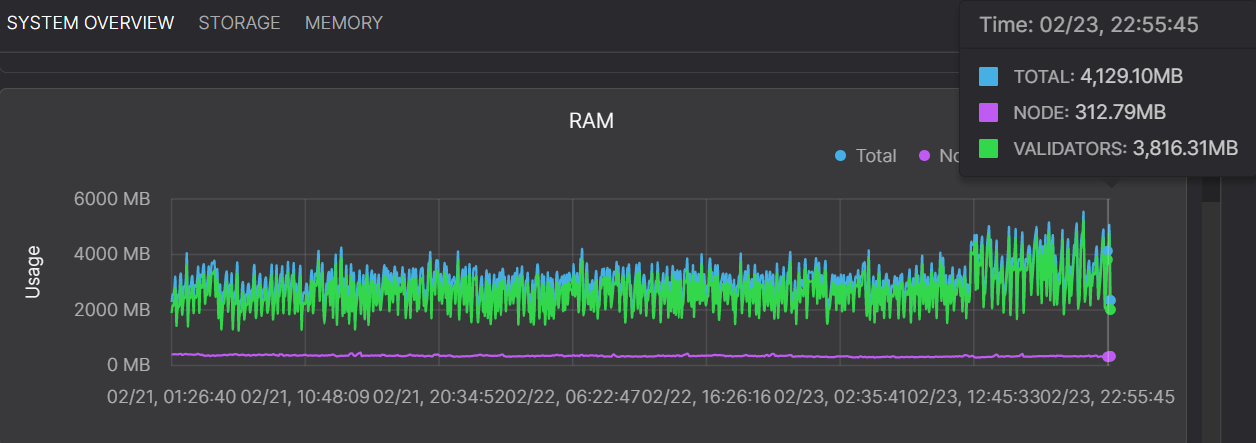
Octez v11 storage RAM usage
TezEdge v1.15 RAM usage
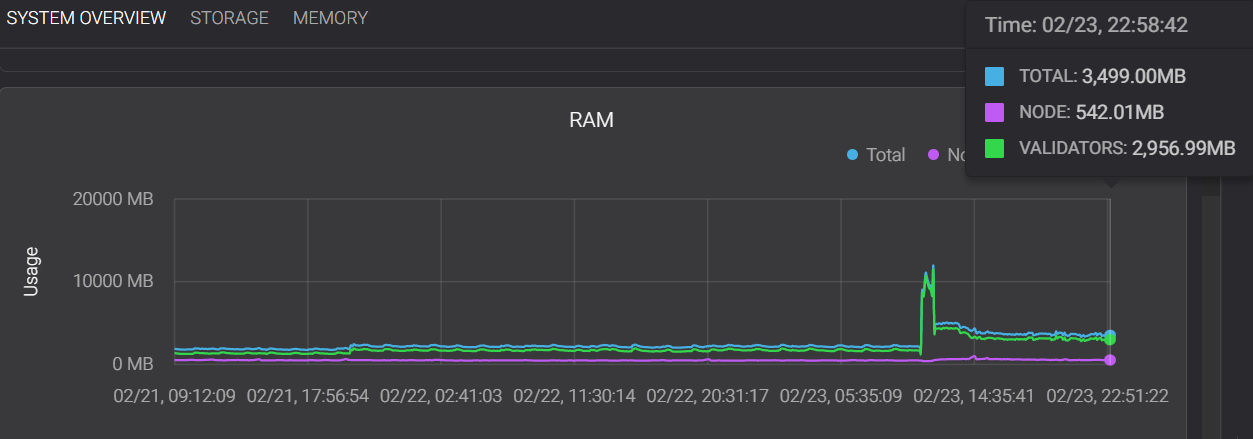
The value to watch here is the green line marked as VALIDATORS. Here you can see that the new TezEdge v1.15 storage uses less memory and it also has much less variance — it does not go through ‘spikes’, sudden rises in the use of memory, which, as you can see in the first graph, are very frequent in the Octez v11 storage implementation.
Please note that the large spike in the TezEdge v1.15 RAM graph is caused by the update to protocol 011 Hangzhou. This included a major restructuring of the context tree, which is a very expensive operation. While the new representation of the context tree is better, it takes a while to migrate the past version’s tree to the new one.
COMMITs are the most significant bottleneck for storage performance
Octez v11 storage duration of commits and checkouts

TezEdge v1.15 duration of commits and checkouts
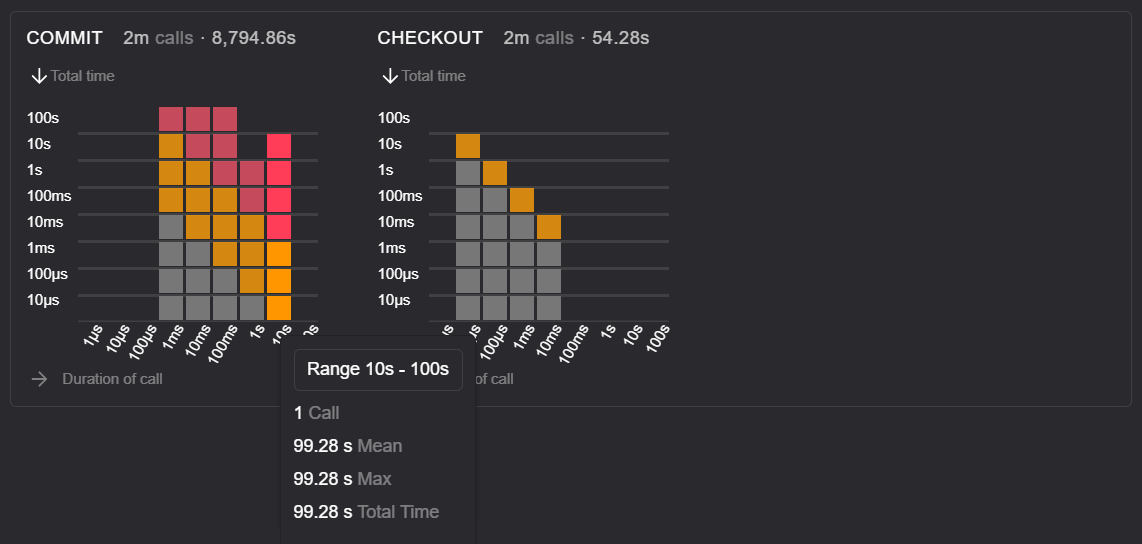
Here we can see that the COMMIT time is faster in the TezEdge v1.15 storage. This is because, during the previously-discussed storage freezes in the Octez v11 storage, actions slow down considerably. Freezes are caused by index maintenance tasks, which do not happen in the TezEdge v1.15 storage. These freezes lead to spikes in latency, which means certain calls can take too long and cause bakers to miss out on their reward for baking or endorsing.
Octez v11 storage duration of MEM and FIND actions for smart contracts
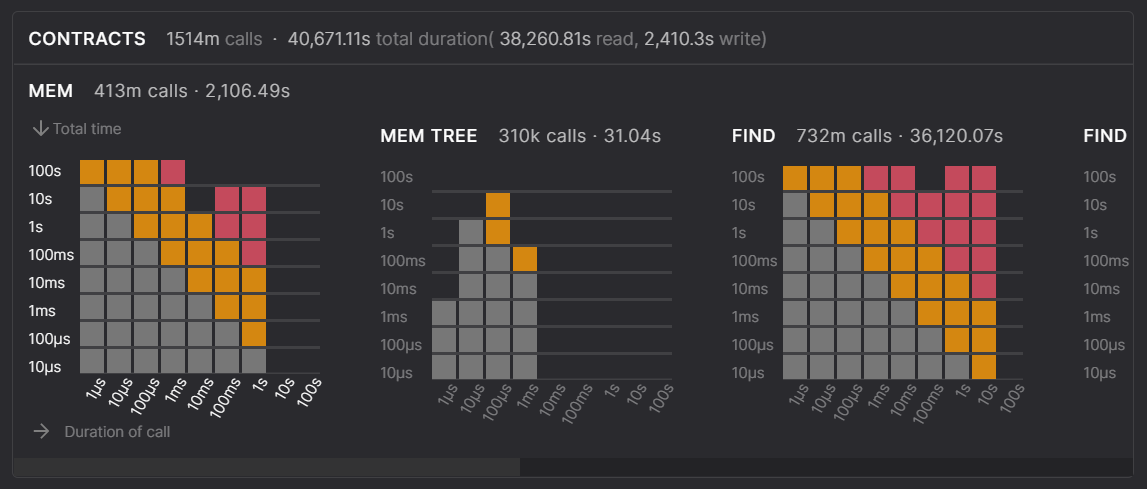
TezEdge v1.15 duration of MEM, MEMTREE and FIND actions
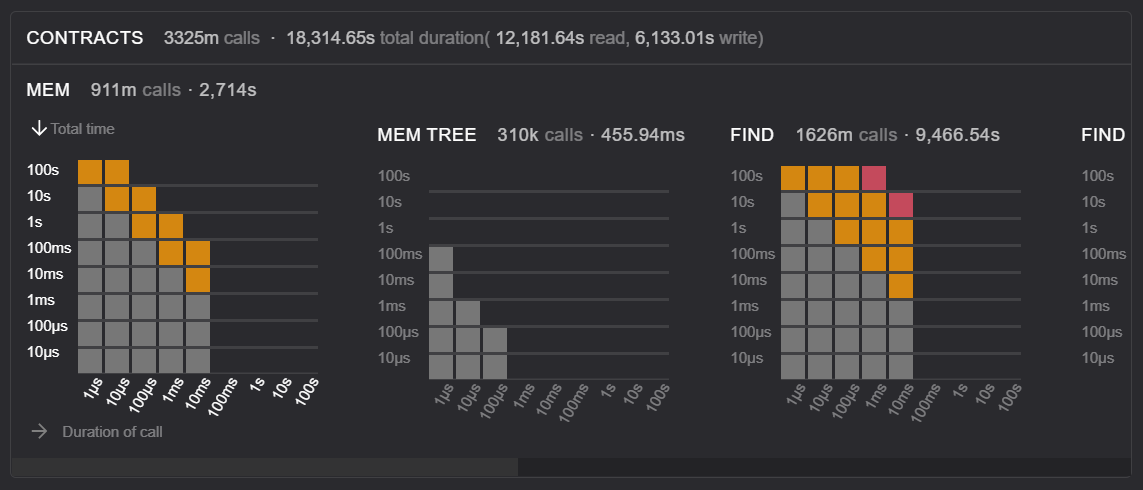
Similarly to COMMIT and CHECKOUT, the actions MEM, MEM TREE and FIND as well as several others in this row are significantly slower in the Octez v11 storage.
See for yourself and now test the new and improved storage
You can see the improvement in the performance of the TezEdge v1.15 storage by running two instances of the TezEdge Explorer, one for the node with the Octez v11 storage implementation and the other for the node with the TezEdge v1.15 storage implementation.
- First, you need to clone this repo.
git clone GitHub - tezedge/tezedge: Tezos node/shell in Rust.
- Then change into the cloned directory
cd tezedge
- Run docker by typing these commands:
a) To test with Octez v11 context storage (Irmin 2.9):
docker-compose -f docker-compose.storage.irmin.yml pulldocker-compose -f docker-compose.storage.irmin.yml up
And visit http://localhost:8181 in your browser.
b) To test with TezEdge’s v1.15 persistent context storage:
docker-compose -f docker-compose.storage.persistent.yml pulldocker-compose -f docker-compose.storage.persistent.yml up
And visit http://localhost:8383 in your browser.
In our next release, users will be able to load the in-memory storage that we described in our past article from a persisted version, which means you won’t have to start processing the entire chain from the beginning each time you start the node. We will also include support for making snapshots of the Tezos blockchain for quicker bootstrapping. However, please note that our snapshots are not compatible with Octez snapshots.
We hope you have enjoyed our article about the new and improved storage. Feel free to contact me by email, I look forward to receiving your questions, comments and suggestions. To read more about Tezos and the TezEdge node, please visit our documentation, subscribe to our Medium, follow us on Twitter or visit our GitHub.



