Earlier this year, the Mumbai protocol upgrade had successfully halved block time from 30s to 15s. The Nairobi protocol, the one currently governing Tezos Mainnet, introduced further optimizations to reach consensus faster. For Tezos to remain a cutting-edge blockchain, we plan to reduce latency further, taking minimal block time from 15s to 10s in an upcoming protocol P upgrade proposal.
This post aims to give the community a heads-up on the upcoming changes in order to make sure we are all ready.
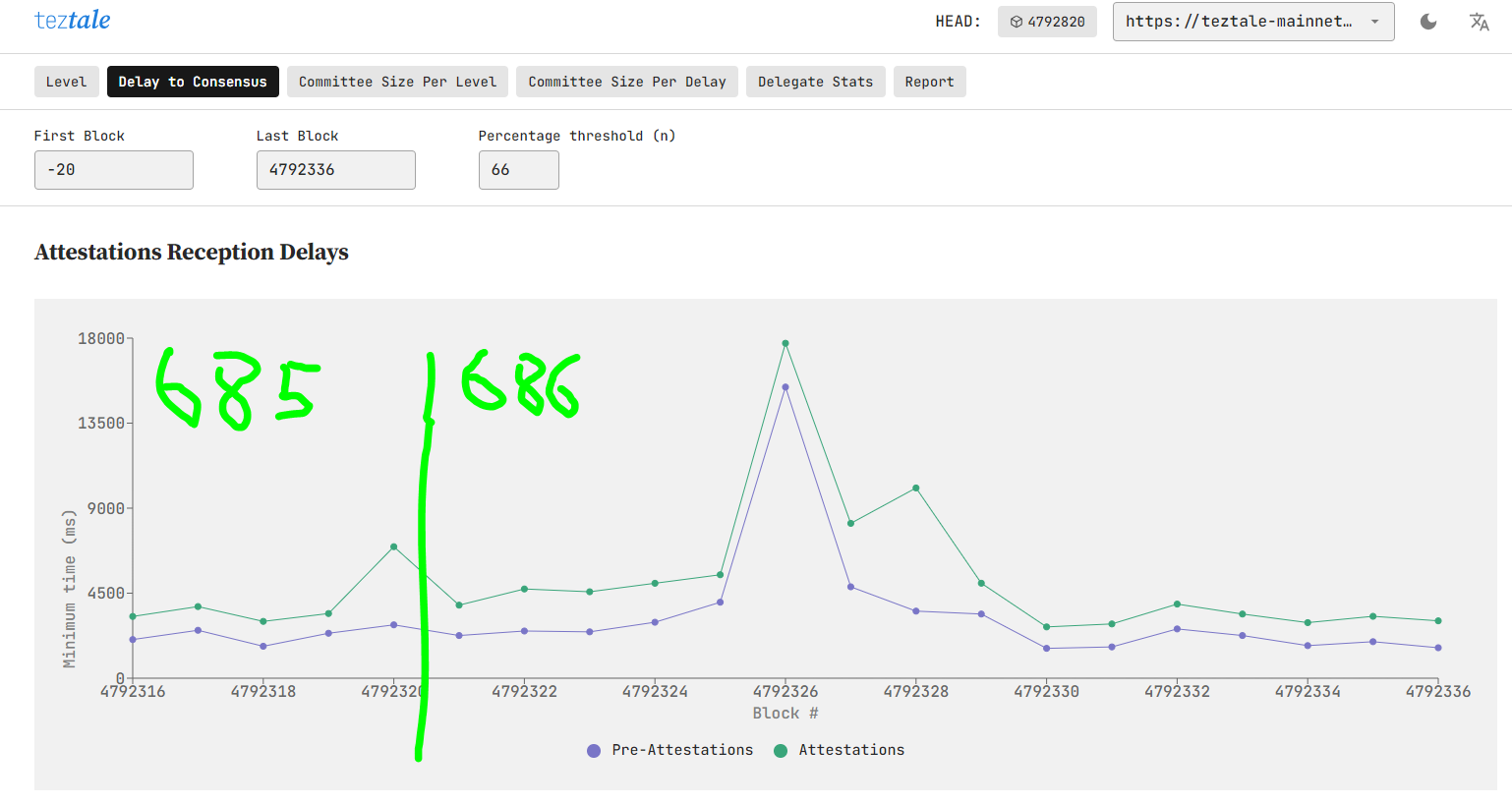
Over the last few months, we developed a testing and profiling framework which simulates the behavior of Tezos Mainnet under stress – i.e. under a full load. We had two goals: the first was to analyze Octez and improve its overall performance. The second was to measure the impact of these changes in a realistic lower-latency environment.
These experiments enabled us to identify major bottlenecks in Octez. We then fixed them one by one incrementally, and validated their impact again using this custom-built framework. The results give us enough confidence to propose reducing block time in the next protocol proposal.
It has always been our core belief that bakers should be able to participate in Tezos consensus with affordable, lower-end infrastructure. This is a core strength of Tezos which inherently impacts decentralization, so we want to preserve it as Tezos evolves.
Therefore, our experiments included setups with the following specification:
- 4-core Intel CPUs @ 2.80GHz (we tested both arm64 and amd64/x86-64 architectures).
- 8GB of RAM
- SSD-like I/O performances
- A 100Mbps network bandwidth
As for signing blocks and operations, our experiments simulated a signing delay of 1s, a ballpark figure comparable to a Ledger Nano S’ performance.
With the implemented optimizations and the configuration above, we managed to deterministically achieve successful experiments that determined that a full-load Tezos Mainnet would be safe with a minimal block time of 10s – where safe means that more than 99% of blocks are produced at round 0.
We plan to publish a blog post detailing the full methodology and the results obtained during this project. In particular, we will show that we could go for more ambitious latency reductions assuming high-end configurations.
In the meantime, we kindly ask you to use this thread to share with us details about your baking setups, ask further questions, and raise any concerns you may have.