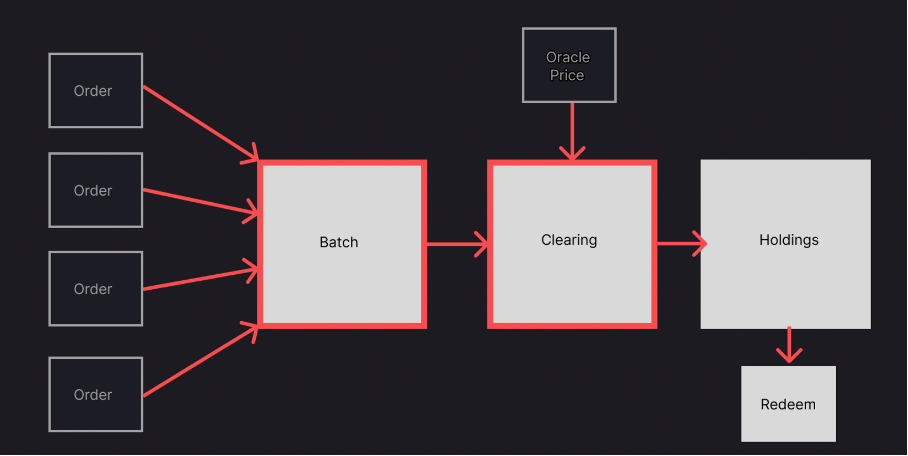
In this post we will introduce Batcher; how it works and why it is different from other DEXs. We refer to Batcher as a batch clearing DEX. This is due to its behaviour of collecting all orders for potential swaps into a batch to be executed at a point after the batch is closed (i.e. no more swap orders can be placed)
The aim of the batch clearing dex is to enable users to deposit tokens with the intent of being swapped at a fair price with bounded slippage and almost no impermanent loss.
In comparison to standard AMM type DEXs, Batcher does not have a liquidity pool behind it; it is more akin to an order book DEX rather than an AMM.
Users can deposit tokens during a deposit window; all deposits during this window will form the ‘batch’. Once the deposit window is over the ‘batch’ is ‘closed’. The batch remains closed until Batcher receives an oracle price for the given pair. Receipt of the oracle price triggers the clearing of the orders and the results of swaps are stored in holdings and can be redeemed back to the user’s wallet.
In contrast to other DEXs a swap order is not assured to be filled; the result of a deposit for a swap in Batcher could be one of the following:
Filled - Full amount of the order is swapped for the requested token. Batcher was able to find an order or multiple orders on the opposing side to completely swap the token amount.
Partially Filled - Only part of the amount of the order is swapped for the requested token with the remaining left in the original token. Batcher found one or more orders on the opposing side but they were not enough to completely fill the requested amount of token.
Not Filled - None of the amount of the order is swapped. Batcher could not find matching orders to swap the tokens.
Another difference to other DEXs is that users do not define a literal price on a swap order but an offset to the oracle price.
Offset
Price
Chance of order being filled
Oracle Price - 10 basis Points
Worse
Better
Oracle Price
Flat
Flat
Oracle Price + 10 basis points
Better
Worse
Basis Point - One basis point (bp or bip) is equivalent to 0.01% (1/100th of a percent) or 0.0001 in decimal form. For example, 10 basis points is equivalent to 0.1% or 0.001 in decimal form.
When the batch is closed and the oracle price is received, Batcher will try to find which of the three levels will clear the most orders; this is deemed the clearing price. This level is then used to match orders on a first come, first served basis. The level chosen by a user will depend on their own context and intent behind the swap. If, as a user, I want a better chance of a large trade being filled and I am willing to except a lower price I can choose ‘Worse Price /Better Fill’; meaning than more counterparties on other side of the trade will likely be interested in the swap and that will maximise the chances of the swap being completely filled. If, however, I am not in a hurry to make the trade and want to hold out for a slightly better price then I can choose ‘Better Price /Worse Fill’; meaning that I will maximise the chances of swapping at a slightly better price than the oracle price but there is more chance that my order won’t be filled in this batch. If I am agnostic to a worse or better price then I can choose the oracle price.
How to?
The Batcher UI is deployed to both Ghostnet and Kathmandunet. In order to use the Batcher UI, you will need the testnet representations of the tokens in the pool; these are available via the Marigold faucet.
The aim of the batch clearing dex is to enable users to deposit tokens with the intent of being swapped at a fair price with bounded slippage and almost no impermanent loss.
In the general sense IL is loss by doing something other than holding the token. If you want to swap to tzBTC but don’t get filled then you would miss out on any gain as opposed to using a different type of DEX where you could potentially get swapped immediately and hold the token for the gain.
I am not sure if I can follow your explanation. You can experience Impermanent Loss when you provide liquidity in a trading pool.
Impermanent loss is better defined as an opportunity cost. Put simply, impermanent loss occurs when you provide liquidity to a given pool and the price of your assets in the pool changes
You want to add liquidity to an ETH/USDT pool. You need to add ETH and USDT at a 1:1 ratio. To keep things simple we’ll say you deposit 1 ETH and 100 USDT. In this instance - we’ll say the price of ETH is $100 to keep the maths simple. So between your 1 ETH and 100 USDT - you’ve got a $200 total value.
In the pool overall, there’s 10 ETH and 1000 USDT. So you have a 10% share and you’ll earn 10% of the trading fees from the pool.
The way AMMs like Uniswap work is with a constant equation:
x * y = k
X and Y represent the quantities of two tokens in a given liquidity pool, while K is the constant value. In this instance 10 ETH * 1000 USDT = 10,000. This has to remain constant before and after any trades in the pool.
Now let’s say ETH rises to 400 USDT - but the liquidity ratio in the pool still reflects the old price. Arbitrage traders will seize this opportunity. These are traders that spot discrepancies in prices across different markets and buy and sell the same asset in order to profit from those price discrepancies.
In this instance, arbitrage traders would buy ETH at a lower price from the liquidity pool until the price is inline with other markets. By the end of it, we’d have 5 ETH and 2000 USDT in the liquidity pool. But the the constant value would still be the same: 5 ETH * 2000 USDT = 10,000.
If you decide you want to withdraw your funds, you’ll get back 10% of the pool - which would now be 0.5 ETH and 200 USDT, so a total of $400. We’ve ignored trading fees up until this point, but let’s say you also made an additional $20 in trading fees - giving you a total of $420.
However, had you never added your ETH and USDT to the pool, you’d have 1 ETH worth $400 and 100 USDT worth $100. It’s a kind of opportunity cost.
It’s called impermanent loss because if you don’t withdraw and the ratio in the pool returns, you won’t have lost anything. As well as this, in many instances your trading fees will effectively negate any loss.
We used a stablecoin in our example. Pools with stablecoins tend to actually have less exposure to impermanent loss as the assets are less volatile. In instances where you’ve got two volatile assets, the losses can be much greater.
At a basic level - the larger the price change, the greater the loss. But your loss only becomes permanent if you withdraw your capital from the liquidity pool.
So please forgive me but when we look at this example it does not seem to me that we are talking about the same thing?
Can the batcher be explained by providing an example ? Initially I thought both buy and sell orders are received in the batch and are matched as per the offset but again in that case there wont be any need for price from oracle. So I am bit confused.
Hi,
We ‘collect’ buy and sell orders whilst the batch is open. Once the batch is closed (i.e. no more orders can be added to the batch) we wait for an Oracle price. Once received, Batcher knows what that price is, the volume of orders, and price levels chosen on both the buy and sell side, thus it can find the price level where the most orders will be cleared.