Designing a Name Service - Part 2: Namespace and Structure
This article is also available as part of our Tezos Name Service publication on Medium. That’s where you can find our future articles on the topic as they become available, but we will post them here too for easy discussion.
In the introduction, we referred to the DNS, which is a system most of us are probably very familiar with. There are however other ways we can envision structuring names in our system. Let’s explore some possible options and examples of projects using them.
Flat Structure
You can imagine the structure simply as a table where a name corresponds to an address value (or values). There are some strong advantages of using a basic approach like this - the logic is straightforward and predictable, access control is easy to implement and the idea is generally understandable to all participants.
E.g.
| Name | Address | Owner |
|---|---|---|
| alice | tz1VSUr8ww… | tz1VSUr8ww… |
| bob | tz1WCd2jm4… | tz1MXFrtZo… |
| … | … | … |
Example: Namecoin
Namecoin started as a fork of the Bitcoin project, providing an extension to the DNS. People could register domains using Namecoins - by registering a name in the form of d/somedomain, the corresponding domain somedomain.bin would become resolvable for the end users. However, the .bin TLD was never acquired as a generic TLD. To make use of Namecoin domains, the user has to install additional software or configure their device to point to a DNS server able to resolve the .bin domain.
An identity service called OneName initially also used Namecoin as the underlying blockchain, but have moved to a different blockchain solution since then.
Hierarchical Structure
Applying a tree structure to represent parent-child relations between names can expand our possibilities quite a bit. Every name becomes a node in a tree. In this tree, we can impose rules that can affect the child nodes or particular nodes. We can also make ownership transitive - that is, the owner of a node can effectively control all descendant nodes as well, not just the immediate children.
In DNS, a node is expressed in the form of <label>.<parent> where the parent is a node expressed using the same format. The only exception is the root node, which is represented by the empty string. All software in the DNS ecosystem these days omits the trailing dot, so for example google.com. becomes google.com. This notation became the de-facto standard for other similar systems like the ENS and the GNS and we will use it in this article as well.
E.g.
(root)
|
[ tez ]
/ \
[ alice ] [ bob ]
/
[ pay ] <== respresented as pay.alice.tez
Example: GNU Name System
The GNS has been suggested as a more secure and decentralized alternative to the DNS as part of the GNUnet protocol stack. It’s interesting as a concept that prioritizes security and total decentralization. The names are not guaranteed to be global. Instead, users map names to values themselves or delegate mapping to other participants in the network. This is sometimes called a petname system - where names are private and non-global.
Example: Ethereum Name System
The ENS is a relatively new project built on the Ethereum blockchain with the same goal in mind:
ENS’s job is to map human-readable names like ‘alice.eth’ to machine-readable identifiers such as Ethereum addresses, content hashes, and metadata. ENS also supports ‘reverse resolution’, making it possible to associate metadata such as canonical names or interface descriptions with Ethereum addresses.
It is inspired heavily by the DNS and shares the same hierarchical structure, naming scheme, and some of the terminology.
At the time of writing this article, the ENS has over 350,000 domain registrations and a little over 450,000 records total. The system enjoys wide support in software wallets and dapps, for example, here is MetaMask resolving a domain:
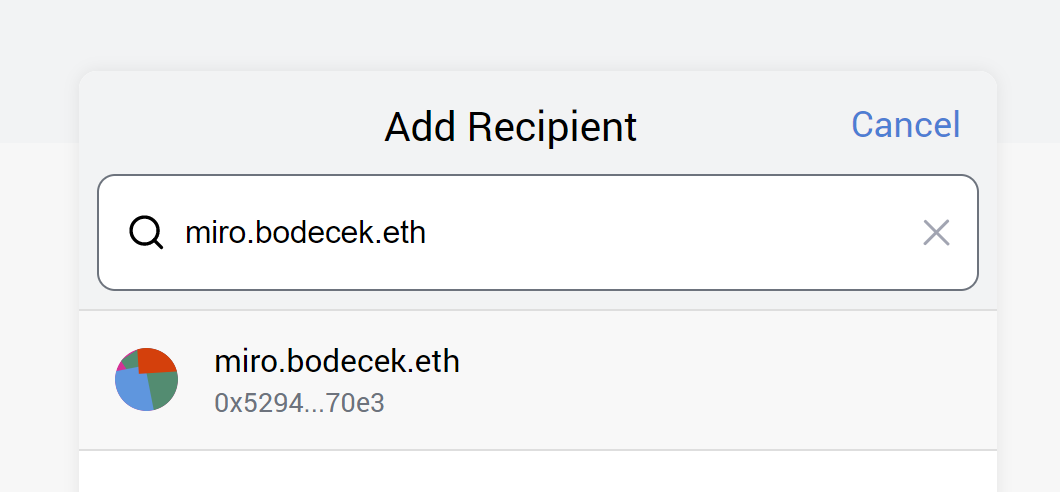
There is a lot of material available online on the topic of ENS. In our series we would like to focus on a few interesting decisions taken by the ENS team, which we could learn from.
Namehashes
ENS introduces the concept of namehashes. Instead of sending names in a publicly readable format, the names are first processed by the client using a recursive one-way function. If we represent our name as a list of labels (e.g. [pay, alice, tez] instead of pay.alice.tez), the function looks like this:
namehash([]) = 0
namehash([label, ...]) = keccak256(namehash(...), keccak256(label))
This approach has some interesting consequences:
- The smart contracts rarely have to deal with strings, which means saving on gas costs and simplifying the implementation. This also means no possibility for on-chain validation or normalization.
- Because all keys are hashes, different types of records can be indexed using one structure - forward records, reverse records, and identity information all together.
- The domain names become somewhat opaque to other users, protecting the names from naive listing. Simply put, you can find to what address any domain resolves, but you cannot reveal all subdomains of a domain in their readable form.
Regarding the last point, we say “somewhat opaque” because there are two major caveats making the matter a bit confusing:
- Second level domain registrations are sent in plaintext during registration, so they are visible to everyone.
- Given a domain, all subdomains are naturally susceptible to revealing via rainbow tables. The official manager app even exploits this by showing 3rd level domains in plaintext, as long as they can be found in a rainbow table. E.g.
accounting.company.ethis easily revealable becauseaccountingis a dictionary word, butdepartment965.company.ethisn’t.
To understand why rainbow tables work, we have to take a look at the signature of the method responsible for creating a new child node:
function setSubnodeRecord(bytes32 node, bytes32 label, address owner,
address resolver, uint64 ttl) { ... }
As you can see, node (i.e. the parent namehash) and label are sent separately and then packed and hashed on-chain, leaving the label susceptible to a lookup in a simple keccak256 rainbow table.
This creates uncertainty about whether the names are in fact hidden or not. In my personal opinion, using namehashes in our name service can be useful, but not as a masking feature. Using it to reliably hide domains is not possible and I’m not aware of any function with the same recursive property that would achieve it. Because of that, we think revealing all names explicitly is the better choice.
Modular Architecture
The whole ENS is a fairly modular system, comprised of several components that act together:
- Registry is the central smart contract where basic information about each domain is stored: the owner and the resolver. It implements an authorization mechanism so that only owners can act on nodes or their children.
- Resolvers are smart contracts that offer resolution logic for different types of records. The resolution mechanism is a two-step process - the client first finds the relevant resolver by looking in the registry and then calls the resolver to obtain the final address (or other value). Domain owners can write their own resolvers or use the default
PublicResolver, which offers a standard implementation. Unfortunately, resolvers can’t be implemented on Tezos as of now, but it might be possible in the future with a synchronous read-only call mechanism. - Registrars and controllers act as gateways enabling participants to register second-level domains. Typically the first-in-first-served registration process will involve calling the controller of a top-level domain using a commit-reveal scheme. The controller will then check that the domain is free and make the necessary changes to both the registrar and the registry smart contracts. Finally, it transfers the ownership of the second-level domain to the new owner.
Decomposition to this level might be challenging given technical limitations in Michelson, but we think that using a modular approach is the right direction to take.
DNS-Bound Data: Monero’s OpenAlias
OpenAlias is another interesting project. It tries to find a pragmatic solution to the problem by storing data inside the DNS system. OpenAlias records are nothing else than TXT records on fully qualified domain names written in a special format.
For example, you can easily see what donate.getmonero.org resolves to by checking in a DNS lookup tool:
oa1:xmr recipient_address=44AFFq5kSiG...P3A;
recipient_name=Monero Development;
tx_description=Donation to Monero Core Team;
This means the whole system is based off-chain and domain ownership is simply implied by the ownership of the corresponding domain in the DNS. Suddenly the problems like pricing, structure, and internationalization are solved by the DNS. We admit it is a tempting proposition - after all, if there is already a reasonably secure and somewhat decentralized solution, why not use it.
However looking at it more closely, there are some problems with it. Firstly, DNS is not as decentralized as we would want it to be. Centralization happens on the TLD registry level and also at the root level - the ICANN. Domain seizures happen and there are other ways authorities can project power towards participants in the DNS system.
Secondly, because the DNS system is already primarily used for resolution of network addresses, the domains are scarce and unreasonably priced. Most owners of DNS domains care little about OpenAlias, but they are the ones who setting the prices and holding available names. We think that the market price for the DNS domain “tezos.com” should be different from the Tezos address “tezos.com”, but under OpenAlias, they are tied.
Finally, building a UI for users to be able to register names in this system is not easy. Domains have to be bought from a DNS registrar and then equipped with a TXT entry in a given format.
On Name Scarcity
In the introduction, we have mentioned the availability of meaningful names as an important aspect. Under a system where names are affordable and users can pick a name to their liking, the selection of names tends to exhaust pretty quickly. It’s easy to imagine that the first John Smith in the system will be able to pick johnsmith.tez, but as we get closer to the 10,000th John Smith, we are going to see a lot of names looking like john-william-smith-932.tez. This is a difficult problem to truly solve in any system comprised of meaningful names that is also globally consistent.
Alternative #1 - Mnemonics for Identity
Let’s leave the idea of designing a vanity system for a second. John Pressman already introduced possible mnemonic schemes of identity systems in his article - like the Urbit ID system or Adam’s mnemonic system, which converts any 32-bit identifier from and to an alias like far-cab-raw-tap.
Such systems have some great advantages: they don’t exhaust the name space quickly and they are fair in the aliases they assign. You could argue that fairness comes at a price - all names are equally meaningless. Indeed we think they don’t meet two of the key goals - usability and internationalization. Still they can give us a valuable perspective on the problem.
Alternative #2 - Co-existing Schemes
So far we discussed the availability of vanity names under some sort of global namespace. However, under a hierarchical system, we could employ different naming schemes linked to each top-level name. This opens up some interesting choices.
For example, we can imagine a hybrid scheme under the top-level name people, combining vanity names with generated names. Our system could generate two additional bytes and transpose them according to a mnemonic system, then add them as a suffix to the name picked by the user. People registering the name johnsmith could still get unique names, e.g. johnsmith.pop.car.people, johnsmith.fig.dog.people and so on. Adding two generated syllables would effectively boost the space of meaningful names by a factor of 65,536.
You could argue that such a system would hardly be any fairer because the added fairness would be only relative to this additional people namespace and the names with higher perceived values would still live under tez where people can register names without limitations. Still, this example serves to demonstrate how a hierarchical system can deploy different naming schemes for different needs.
Summary
We have explored ideas for possible structures to be used with examples of existing projects using them - projects that live both on and off-chain. Then we touched on the problem of name scarcity and discussed how hierarchical systems can be useful for introducing different naming schemes living under one system.
Further Reading
- Squaring the Triangle: Secure, Decentralized, Human-Readable Names by Aaron Swartz
- Alternative naming systems (to the DNS) published by Association Française pour le Nommage Internet en Coopération
- An empirical study of Namecoin and lessons for decentralized namespace design by Harry Kalodner, Miles Carlsten, Paul Ellenbogen, Joseph Bonneau, Arvind Narayanan
- Namecoin by Andreas Loibl (2014)
- A Censorship-Resistant, Privacy-Enhancing and Fully Decentralized Name System by Matthias Wachs, Martin Schanzenbach, Christian Grothof (2014)
- Documentation to the ENS
Join the Conversation
We are excited to start a discussion on this topic with the community! Do you have an opinion on what the structure should look like? How to best design the namespace? Let’s share ideas.
And if you want to chat, come join TNS Group on Telegram!


