Whenever the complexity of a system increases, there will also be increased room for mistakes and errors. That means that whenever we increase sophistication, we must pay even more attention to identifying vulnerabilities.
In software development, conventional debugging techniques can only take you so far. We need to thoroughly test our software by putting it through a great deal of unique and unexpected situations, the purpose of which is to detect vulnerabilities that would be otherwise hidden from us.
One method of achieving that is a technique known as fuzzing (also referred to as fuzz testing), in which software is tested by being fed a large amount of generated inputs, the purpose of which is to capture adverse behaviour that could potentially cause vulnerabilities.
Fuzzing is one of the most effective, automated ways to identify software vulnerabilities. It finds vulnerabilities often missed by static program analysis and manual code inspection. It is an effective way to find security bugs in software and is rapidly becoming the standard for critical enterprise systems. Fuzzing is particularly useful in identifying so-called corner cases — situations that occur only outside of normal operating parameters.
A fuzzer works by generating a large amount of pseudo-random inputs, processed and evaluated by the targeted program to generate situations which the program does not expect.
The fuzzer monitors the program by running it and detecting whenever it crashes, gathering all the data necessary to troubleshoot the issue, such as what input data caused the failure and the stack trace.
This way, the fuzzer is able to record if an input leads to unexpected behavior.
When a vulnerability is triggered, the fuzzer can detect what was happening at that moment, and generate logging activity to find the root cause of the issue.
Fuzzing the TezEdge node
In our case, we utilize fuzzing to minimize the attack surface of the TezEdge node. Fuzz testing is used to explore the wider state space and seek out any possible weaknesses. With fuzzing, our short-term goal is to find bugs as soon as possible as well as any regression bugs that might have occurred during the development phase.
Performing fuzzing is part of our long-term objective to ensure that the TezEdge node is ‘airtight’ and that we can verify the behavior of the node is consistent with the native Tezos node.
An automated fuzzer can help a developer in testing system vulnerabilities that are very difficult to find by manual code inspection. It is important to note that there are many different types of fuzzers, each of which has its own set of advantages and disadvantages, making them suitable for various specific situations. So far with the TezEdge node, we have utilized the so-called coverage-guided fuzzing.
Coverage-guided fuzzing
We want to start by detecting the bugs that are more obvious and easier to find.
For this purpose, we utilize coverage-guided fuzzing, which uses program instrumentation to trace the code coverage reached by each input fed to a fuzz target.
Instrumentation is a method of finding out what parts of the code have been executed. In particular places, there are calls to the code. An implementation of that function can keep track of which edges have been executed.
On each edge (linear section of code — path of execution without any branching) of the target program, a low-level virtual machine (LLVM) inserts a call to a particular function. Instrumentation guarantees that a fuzzer will not miss a line of code and that everything will get properly tested.
Fuzzing engines use this information to make informed decisions about which inputs to mutate to maximize coverage. In essence, this type of fuzzing works by providing the parser with mostly incorrect data
The advantage of this type of fuzzing is that it is easy to understand, though it does require some manual work. Also, coverage-guided fuzzers need to be updated whenever there is a breaking change in the codebase.
We use coverage-guided fuzzing for targets that are self-contained, deterministic and can be executed really fast, such as parsing and other functionalities without side-effects.
For the TezEdge node, we used honggfuzz-rs, a security-oriented software fuzzer and cargo-fuzz, a recommended tool for fuzz testing Rust code.
So far, we have fuzzed the following modules of the TezEdge node:
- The Tezos binary encoding module and the Tezos P2P messages module
We fuzzed the Tezos encoding and messages because they are crucial for security since they operate with inputs received from the network.
- The cryptographic module
The cryptographic module is also essential to security used for hashing, public keys etc.
- Some functions of the storage module
The storage is important to the node and we wanted to fuzz functions that rely on user input.
CI tool for Rust code fuzzing
Whenever you code, you want to remove bugs at the earliest possible moment. For this purpose, developers often use continuous integration (CI) tools which let them run tests before a code commit reaches the main branch, allowing them to know when their code was broken, what broke it and how it happened.
We’ve developed a CI tool for automatic fuzzing of Rust code. When implemented, this allows developers to automatically fuzz the Rust code as they are writing it.
For a guide on how to implement the Rust Fuzzing CI, check out our GitHub:
View the results of fuzzing
You can view the results of fuzzing on our website at http://fuzz.tezedge.com/. Click on ‘develop’ and then select one of the merge requests folders (arranged by time, from oldest at the top to most recent at the bottom).
Finally, click on the directory that you are interested in to see various information including code coverage, instrumented lines, executed lines and timestamps.

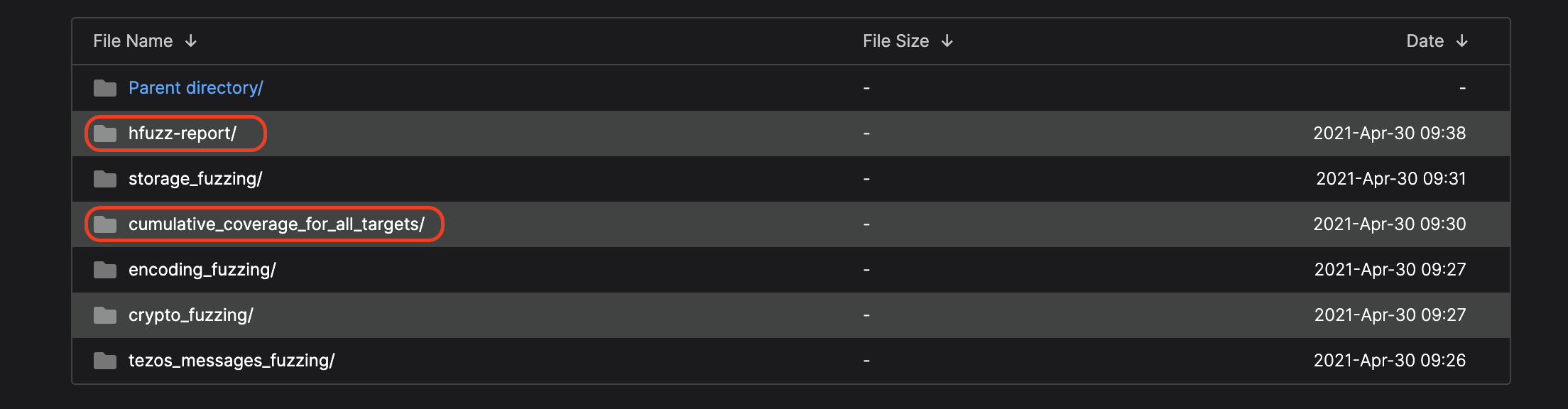
fuzz_report contains report of honggfuzz run (covered/total edges, diffs with previous report, initial state and previous run)
cumulative_coverage_for_all_targets contains a coverage report for all fuzzing targets, while others contain reports for each fuzzing target.
In addition to that, there is also a report on cumulative coverage titled as cumulative_coverage_for_all_targets and a fuzz_report on the progress of the honggfuzz run.
A fuzzer maintains a set of input files, each of which does different coverage. This is called corpus. To render the coverage of this corpus into a user-friendly form, we apply the data from it and create reports on the resulting coverage in the form of HTML files.
When a developer adds or changes the source code and creates a merge request, the fuzzer is automatically launched and begins to look for suitable inputs with which it can test the code, generating a report which we can view to see what was successfully tested and what is still missing.
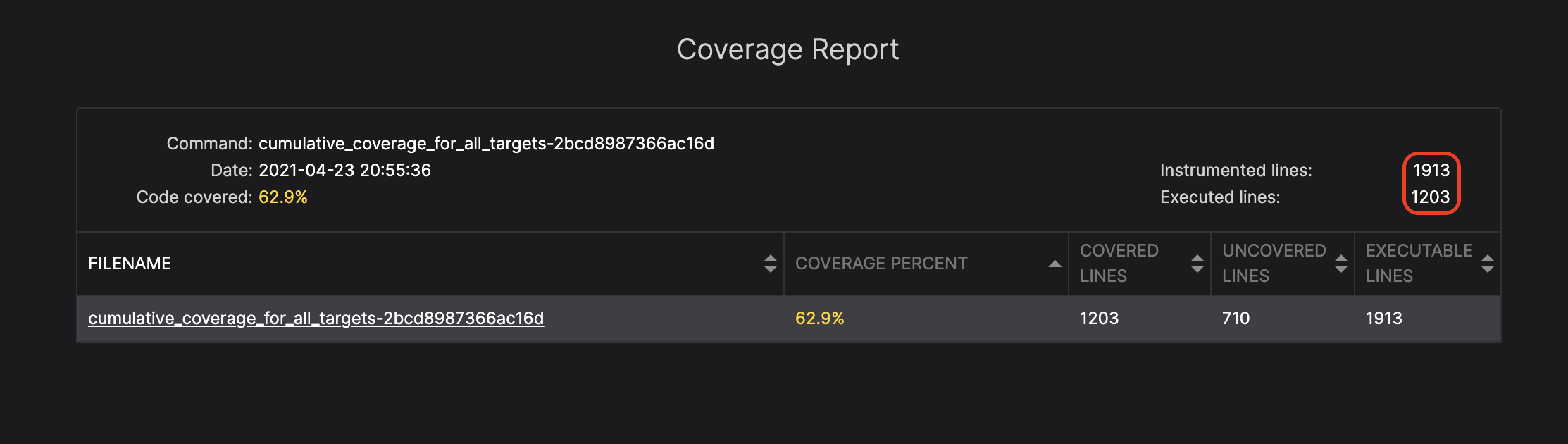
The executed lines value is the number of actually covered lines.
The instrumented lines describes the number of lines that are instrumented for coverage (i.e. it is possible to track if it is covered), meaning that they are executable.
You can see the cumulative report for all files in all modules that the fuzzer instrumented.
In this particular scenario, the fuzzer instrumented 1912 lines and executed 1203 lines.
If the developer wants to increase the number of lines executed, then they must know the exact position of the lines already executed. If we know what is missing, then we know how to adjust the fuzzer accordingly.
Here you can see exactly which lines have been executed:


The leftmost column describes: the number of times the fuzzer executed this specific line / the number of possible executions.
Breakpoints are used to track the number of possible executions. All possible breakpoints are set up and then we record those that have been executed. It is possible to have multiple breakpoints corresponding to the same line, so these are the number of breakpoints hit during execution / the number of breakpoints set to that line.
The colors are a visual aid that describe which lines of code have been tested well enough and which have not. Green marks a line of code that has been successfully tested. Red marks a line that has not been tested, which means that we must adjust the fuzzer to test for these lines.
Since we know which lines have not been covered by the fuzzer, we can add new inputs into the corpus of the fuzzer that will cover more lines of code.
You can see an example below:
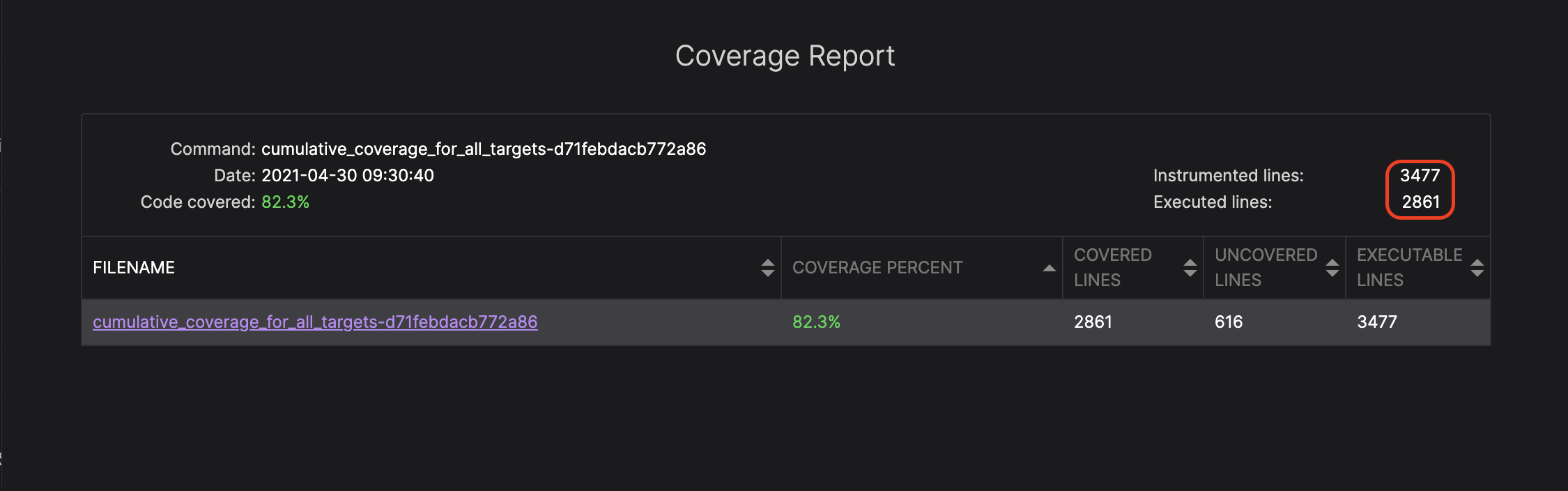
In this screenshot, you can see the increased coverage after adding new fuzzing targets, including the encoding module which is responsible for encoding and decoding messages to and from bytes stream using the Tezos encoding schema.
Fuzzing progress report
Here is a report where you can see the current state of the fuzzer.

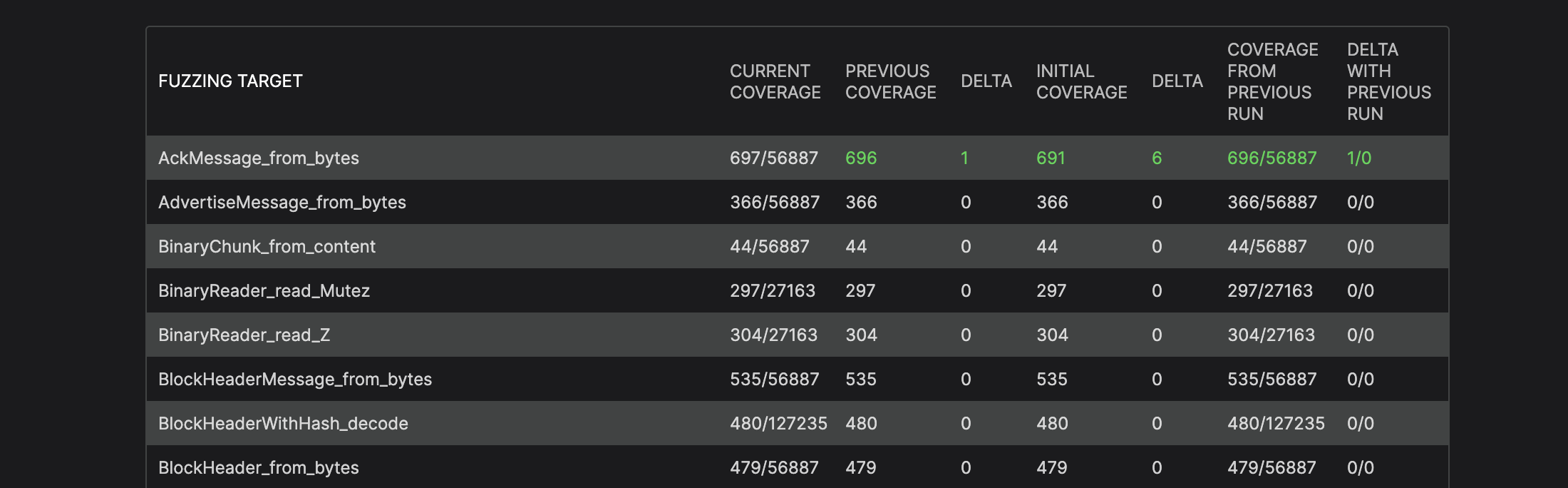
This is information, feedback from honggfuzz for each fuzzed target, we can see the coverage feedback that is used by honggfuzz in the form of covered edges / total number of edges. We can also see increments from previous reports as reports are generated periodically, from the initial state of coverage and the difference from the previous run of honggfuzz.
Fuzzing target is the function we’re fuzzing.
Current coverage describes hits/total edges (instrumented linear paths of application code) as reported by honggfuzz.
Previous coverage is the number of edges previously reported (report is generated each time coverage is changed) with difference.
Initial coverage is the coverage reported at the very beginning of the fuzzing.
Coverage from previous run is the latest coverage reported by the previous run. Green numbers mean that they are improving compared to the previous run, red that they are regressing. N/A is when there is no data to display or compare with.
Delta is the difference between current and previous numbers
Slack notifications
It is also possible to configure the CI tool so that an alert is sent directly into Slack.
Please follow the instructions on our GitHub: GitHub - tezedge/fuzzing-ci: Simple CI program for running fuzzing over TezEdge. and configure the CI tool by editing the TOML configuration file fuzzing-ci/config.toml at master · tezedge/fuzzing-ci · GitHub.
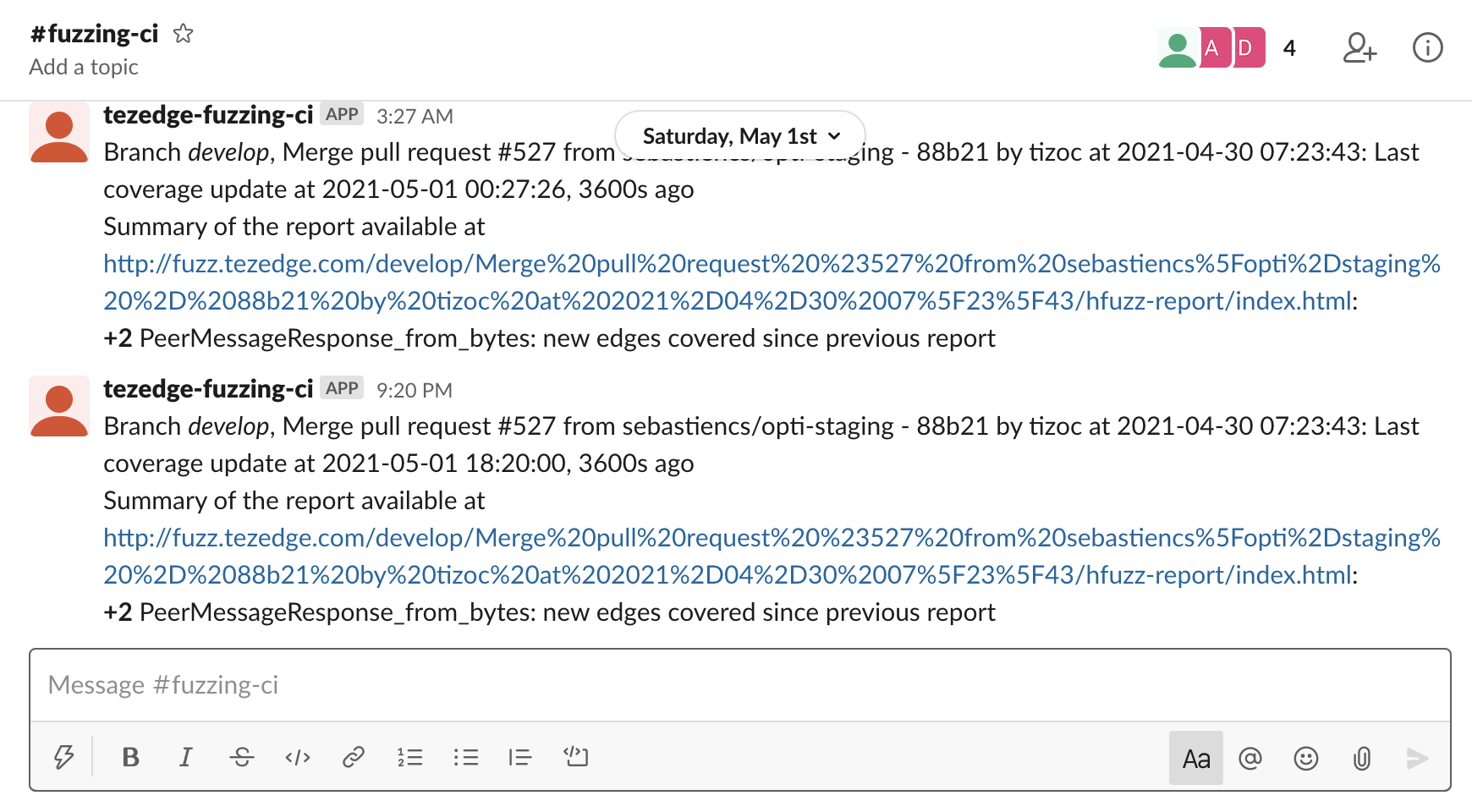
The CI program posts the following kinds of messages to Slack: coverage reports are ready, fuzzing has started, there is progress in fuzzing (i.e. there are new edges discovered by the honggfuzz in one of the targets), there was no progress for a day.
We appreciate your time in reading this article. If you have any comments, questions or suggestions, feel free to contact me directly by email. Feedback is always welcome.
To read more about Tezos and the TezEdge node, please subscribe to our Medium, view our documentation or visit our GitHub.


