In April 2022, Tarides improved the performance of Octez v13 and published a blog post on the progress. Our work resulted in making Octez storage 6x faster, which means we reached our performance goal of 1000 transactions per second (TPS) in the storage layer! Additionally, all storage operations are more stable as their mean has been improved by a factor of 12. Our work on improving the performance continues.
We are also excited to see our contributions adopted in the Jakarta Protocol last month. We added optimised Merkle proofs to the protocol, that we developed as part of the Rollups projects! In the coming month, we’ll be publishing a blog post about Irmin’s Merkle proofs API. Keep an eye out for it on the Tarides blog and follow us on Twitter for notifications on new blog posts, or subscribe to our RSS feed.
Throughout April, we continued our investigations on improving the space usage and performance of Octez by starting integration testing for our layered store, which comes with a garbage collection operation that runs asynchronously so as not to impact the Tezos node’s performance.
If you’re new to Irmin, the Octez storage component, please read more about it on Irmin.org.
Improve the Performance
Improve Snapshot Import/Export
After the activation of Hangzhou, the memory usage during snapshot import and export increased significantly, reaching 8GB. This is because the very large directories in the context (containing a few million entries) are loaded in memory during snapshot import/export.
Last month we released Irmin 3.2, which contains the improvements to the snapshot and we integrated it in Octez v13. We also provided default options for running the import on disk and export in-memory. These are the best configurations for most users, but they are modifiable from the command line.
A bug in the snapshot export was causing the generation of a (slightly) larger snapshot file when using the on-disk option. This is not critical. The snapshots are still valid, and the imported stores are correct. It only occurs when using non-default options for the export. We have determined the cause of the bug, but as we plan to change the layered store’s snapshot format, we won’t fix it for now.
This work is complete, as it is part of the latest release of Octez.
Relevant links: tezos/tezos#4862, mirage/irmin#1814.
Record/Replay of the Tezos Bootstrap Trace
We are working on a benchmarking system to be integrated into Octez’s lib_context. Running benchmarks from Octez directly is important for us to make sure that there isn’t regression in either Irmin or lib_context, but it also allows any other Tezos user to reproduce them or benchmark Tezos with a different storage backend.
As we transition to a new system, we must maintain two sets of benchmarks: the “old” benchmarks running in Irmin and the new ones in tezos/lib_context. We backported the new benchmark system to older versions of Octez (v11, v10, v09) and we ran the benchmarks. For example, the graph below shows a comparison of the TPS performance between Octez 10, 11, 12, and 13 while replaying the Hangzhou Protocol’s first 150k blocks on Tezos Mainnet. Octez 13 reaches 1048 TPS on average which is a 6x improvement over Octez 10!

The full benchmarks for Octez v10, Octez v12, and Octez v13 are available in the blog post for Irmin 3.0.
Generate and Publish Irmin/Tezos Performance Benchmarks
We are automating a benchmarking system that runs monthly and publishes benchmarks regularly. This way we can keep Tezos developers informed of Irmin’s performance. For example, the Elapsed wall CPU Time shows the benchmarks available for the past seven months.
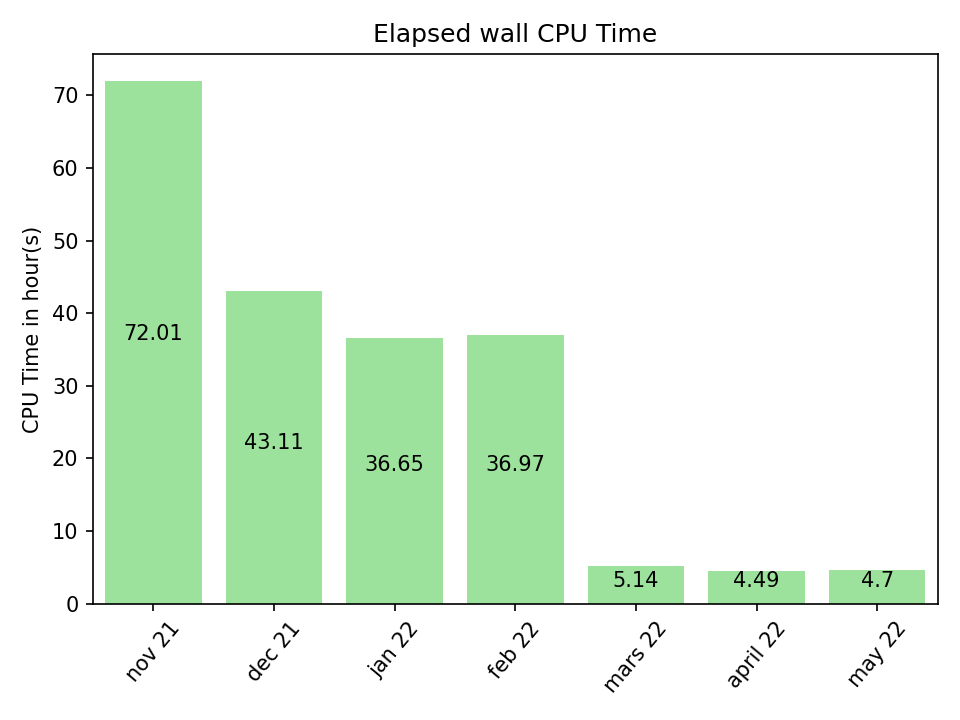
In order to ensure that benchmarks are reproducible, we created an opam lock file with the exact benchmark dependencies for each month. We have one for April and we ran the corresponding benchmarks. We also improved the scripts we use to run the different benchmarks (we have benchmarks running in Irmin and WIP benchmarks running in lib_context).
Automating the benchmarking system is a rolling work since we ameliorate the system as we go.
Relevant links: tarides/tezos-storage-bench#9, tarides/tezos-storage-bench#10.
Plan Porting Irmin to Multicore
OCaml 5 will introduce several changes with the introduction of Multicore. We want to move existing Octez and its dependencies to Multicore in a timely manner, so Tezos can profit from the performance gains. In the case of Irmin, a big step will consist of using eio, an asynchronous and fast I/O that works well with Multicore.
We started our work on porting code to Multicore this month. So far, we ensured that Irmin and associated libraries compile on ocaml-variants.5.0.0+trunk and that the tests run. In doing so, we found a bug in the OCaml compiler. We also started porting irmin-unix and irmin-fs to use eio.
This work just started this month and consists of a lot of changes to Irmin, our plan is to make progress on this in Q3.
Relevant links: ocaml/ocaml#11229
Bound Tezos Memory Usage
In some very specific cases, Irmin’s LRU cache was observed to consume a lot of memory on the latest Tezos protocols. This is due to the fact that some of the objects added to the LRU cache are larger than in previous protocols. Finding the optimal size of this LRU cache is challenging since storing fewer objects in the LRU cache decreases the memory usage, but it also has an impact on the performance of the node. The current size parameters work mostly well, but we are investigating possible improvements to find a better balance for corner-case situations.
A part of the solution is to integrate a different, memory-efficient LRU cache called cachecache into Irmin. This is still a WIP because the API needed for Irmin isn’t yet fully provided by the cachecache library. As a nice additional feature, cachecache is formally specified using Gospel. We also plan to officially verify its extension as part of an internship that just started.
Once cachecache is integrated with Irmin, additional work will consist of finding the optimal LRU cache size and limiting the LRU cache size based on the in-memory sizes of its elements.
This feature is not urgent, as a simple fix consists of limiting the size of the LRUs. We will work on this in Q3.
Add Merkle Proofs
Optimise Merkle Proofs
Blockchains that use "rollups” can process a batch of transactions more quickly by using a secondary blockchain, which then commits the results to the primary blockchain. As we have added Merkle proofs to the Jakarta Protocol, projects can now use Merkle proofs to implement efficient rollups, like the upcoming Transaction Rollups or smart-contract rollups planned for a future protocol upgrade.
We are working on a blog post presenting the API for Irmin’s Merkle proofs. We have created benchmarks to compare both the proof size in binary or 32-Ary trees and the structural vs. the stream proofs. DaiLambda also benchmarked the different libraries for serialising the proofs: tezos/data-encoding, tezos/compact-encoding, and mirage/repr. As expected, the new compact-encoding library developed for Jakarta is the most compact.
For now, the Merkle proof API requires that the tree must be persisted on disk to generate a proof from it. But in some cases, it’s useful to provide a way to produce proofs from in-memory trees instead. To do so, we started working on Irmin’s in-memory proofs and simplifying the provided API to work both on disk and in-memory. We have started the investigative work with the first results leading towards updates to design decisions for the existing proofs.
The complete Merkle proof API will be available for the next release of Irmin, which will be before the end of the quarter.
Relevant links: mirage/irmin#1810, tezos/tezos#2780.
Improve the Space Usage
Integration of Layered Store/GC
Irmin stores the Tezos context in a single store.pack data file. This file is append-only. As new blocks are added to the blockchain, the store.pack file grows larger and larger. As a result, node owners who wish to limit a node’s disk usage periodically export a snapshot of the node state. Then they import them into a fresh node instance, similar to manual garbage collection.
The layered store is a feature that splits the store into layers: one read-write layer that contains the latest cycles of the blockchain, which can still be reorganised and aren’t final, and a read-only layer containing older, frozen data. The layered store feature comes with a GC operation, which periodically discards the oldest cycles and keeps only the recently used data on disk. The GC operation is performed asynchronously with effectively no impact on the running Tezos node. With a layered store for the rolling nodes, the disk space used can be kept small throughout the run of a node. Plus, there isn’t a need to snapshot the export and import when the disk’s context size gets too big. Garbage collection and subsequent compression of live data into a contiguous region in a file may improve disk cache performance, which improves overall node performance.
This feature initially targets rolling nodes. A rolling node only needs to keep the read-write layer. It can discard older data altogether. The next step for the layered store development is to work with archive nodes. These nodes will keep the read-only layer (instead of discarding it, like rolling nodes do). As this read-only layer will contain the full chain history, archive nodes can be used by indexers that need historical data and can allow anyone to bootstrap the Tezos network from the genesis block.
This month we continued improving our prototype’s code and started testing the integration with the tezos-node code. A missing part of the prototype was the support for the read-only instances, which we have now implemented. One current issue is that the layered store does not provide GC for the index. GC’d commits are still available in the index. In the prototype, any attempts to access such commits will fail. We need to decide how to address this, as we want the node to gracefully handle the task of reading GC’d commits.
We are focusing our efforts on the layered store for the remainder of the quarter and plan to have it integrated in the next release of Octez at the end of Q2.
Relevant Links: mirage/irmin#1824.
Disk Usage Analysis
We have also worked on an analysis of an Irmin context that was produced by running a Tezos node after a snapshot import and bootstrapping it for the first two months of the Hanghzou protocol. Based on this, we detected some areas of potential optimisations in the way we store steps on disk and on how the internal nodes in Irmin are generated, for which we opened issues.
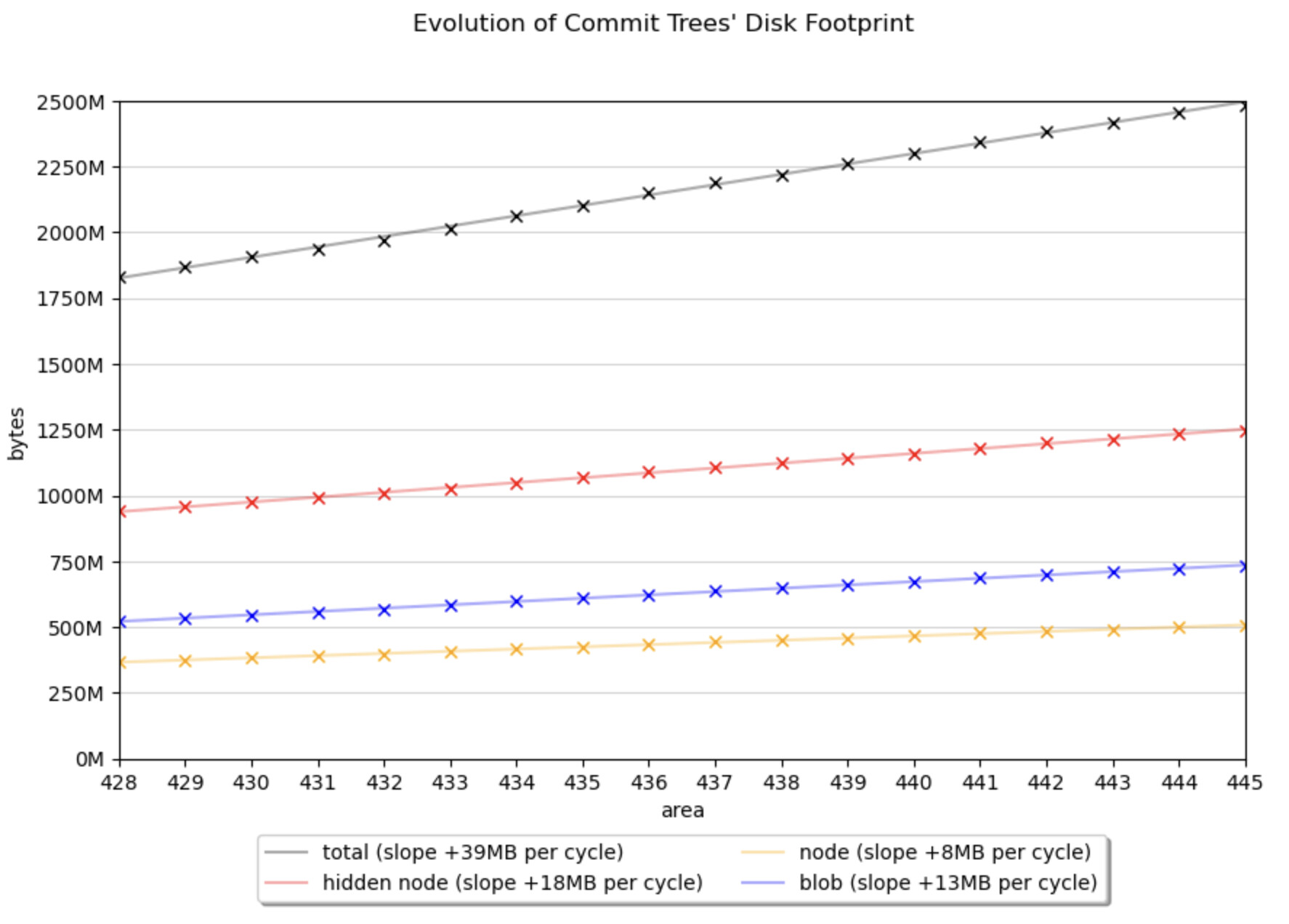
For example, the analysis in the “Evolution of Commit Trees’ Disk Footprint” shows that the commit trees’ growth rate is very stable. Note that in Tezos, a commit’s tree shares more than 99.9% of its disk space with the preceding commit’s tree. This happens because in lib_context the tree of the newer commit was formed by modifying the in-memory tree of the older commit.
In the graph below, we plot the three types of objects of an Irmin tree (blobs, nodes, and hidden nodes). An area or a cycle corresponds to around 8,203 commits.
Zooming further into the commit trees, our analysis of paths in the store groups the objects into eight categories, depending on their ancestor directory. The results show the sharing factor: for example, /data/big_maps/index/*/contents directories have 13.890.632 subdirectories (not visible here), but there are only 5.067.232 unique subdirectories.
As above, in the graph below we plot the three types of objects in the store. The object column is the total of the three, and the byte counts are the disk footprint of the corresponding directory.

The preliminary conclusions of our analysis show that there is room for improvement with the on-disk encoding of irmin-pack and that the layered store’s garbage collection will solve the pack file growth.
Relevant links: analysis of Hanghzou context, mirage/irmin#1807, mirage/irmin#1806.
Improve Tezos Interoperability
Add Monitoring for Irmin Stats to a Tezos Node
Tezos nodes can run with an attached Prometheus server that monitors and reports stats about node execution. The Prometheus server is now integrated into the Tezos codebase. It’s launched by the node when requested by the users. We plan to add Irmin-specific stats to this monitoring system, so users can also inspect them while running a Prometheus server.
The first part of this work consisted of introducing a Metrics module in Irmin that’s responsible for stats gathering and reporting. The global stats used so far become local to a store, which also is necessary for the move to Multicore.
This work is scheduled for Q2.
Relevant links: mirage/irmin#1817
Storage Appliance
Using an Irmin daemon instead of using it as a library, as is the case now in Tezos, potentially reduces the memory usage of the node. Instead of two processes interacting with Irmin while caching things in memory, only one process is used for all interactions within the Irmin context. This also simplifies the semantics of interactions between read-write and read-only instances, as we don’t have to use the filesystem as an inefficient interprocess communication mechanism. The server can also be used to access a remote context, in case there’s not enough storage available locally, for example. Overall, this aims to improve the Tezos interoperability by defining clearer semantics of Irmin interactions and avoiding memory issues produced by excessive caching or data-racing.
The storage appliance work aims to provide Irmin with features for better management of concurrent accesses to the storage. For example, we should have the means to discriminate read-only (RO) accesses from read-write (RW) accesses, such that we could prioritize their treatment at the storage end. We have started this work by integrating irmin-client into the tezos-node in place of the direct calls to Irmin. There is continued work surrounding optimisation and interface changes to maintain compatibility with the existing Irmin interface in libstorage. Some finer-grained items we’ve worked on are improving the client-server handshake in Irmin and designing the addition of specific irmin-pack commands for getting stats and generating snapshots.
Relevant links: mirage/irmin-server#42, mirage/irmin-server#44.
Maintain Tezos’ MirageOS Dependencies
General Irmin Maintenance
We released Irmin 3.2.1 in order to fix the dependencies issues, due to breaking changes in the new release of cmdliner. Irmin’s irmin-http backend is still not supporting the structured keys feature introduced by Irmin 3, but fixing it will require more work than we initially planned.
Please remember to read our blog post on the Tezos improvements and how we reached 1000 TPS. Subscribe to the Tarides blog to read on your favourite RSS reader.


