In February 2022, Tarides continued to make progress on scaling the Tezos blockchain. First with scaling single-node operations, by optimizing Octez disk and memory resource usage, we managed to double Octez transactions per seconds (TPS) in our synthetic benchmarks! Second with scaling the economical protocol, we added Merkle proofs to the J protocol proposal that will be used in the upcoming implementations of the L2-layer rollups.
In order to better use baker resources, we also worked on a new and improved rolling mode for Octez, which will keep the amount of data on disk constant. We focused on finishing up a design document for that feature (called layered store), and we implemented an initial prototype. .
We have also contributed to various improvements in the upcoming Octez v13 release. For instance, we’ve proposed a solution to address the Hangzhou memory consumption issue that appears during snapshot imports and exports.
If you’re new to Irmin, the storage component used by Octez, please read more on our website Irmin.org.
Improve the Performance
Improve irmin-pack I/O Performance
We have been working for a few months on improving the I/O performance of irmin-pack by implementing the structured keys feature. irmin-pack, the Irmin backend used in the Tezos storage layer, writes data in an append-only file called a pack file. In order to efficiently retrieve the data, it uses the Index library, which maps hashes of objects to their location in the pack file. The structured keys feature consists of adding more information in the keys (and not just the hash) to avoid accessing the Index for every read. This new method leads to fewer stored objects in the Index at the cost of some potential duplication of objects on disk.
With structured keys, we can choose between two indexing strategies: the minimal indexing strategy, which only adds the commits to Index and duplicates all nodes and contents under the commits, or the always indexing strategy, similar to the current implementation, where all objects (commits, nodes, and contents) are added to Index.
With the minimal indexing strategy, the numbers of I/O syscalls are drastically reduced, resulting in doubling the TPS for replaying the bootstrap trace. We are still benchmarking this new feature, and we are writing a blog post that will show the final benchmarks. We expect these improvements to increase the reliability of baking rewards and to decrease the gas costs used to perform transactions.
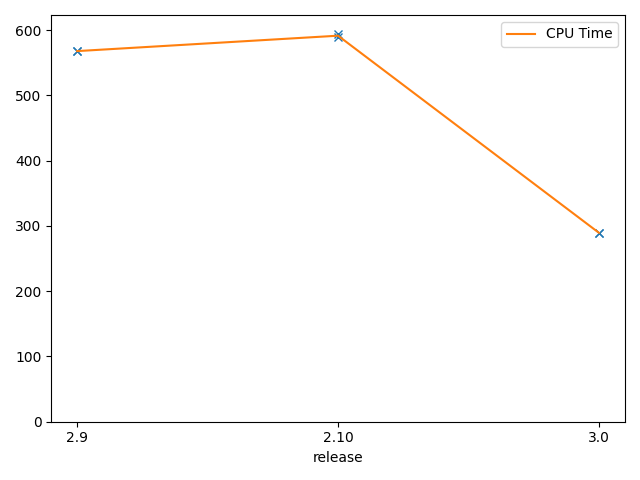
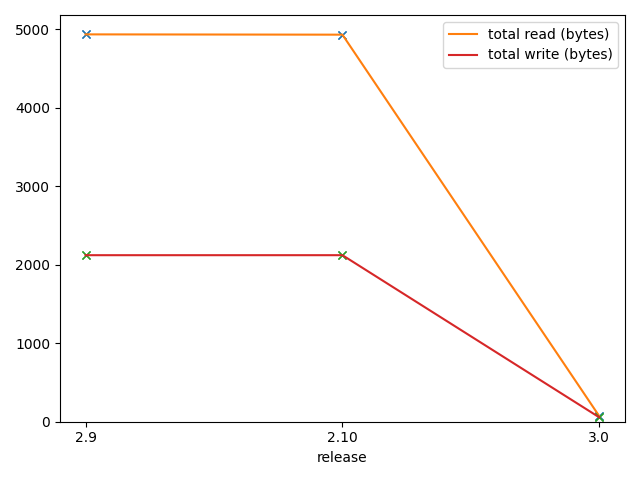
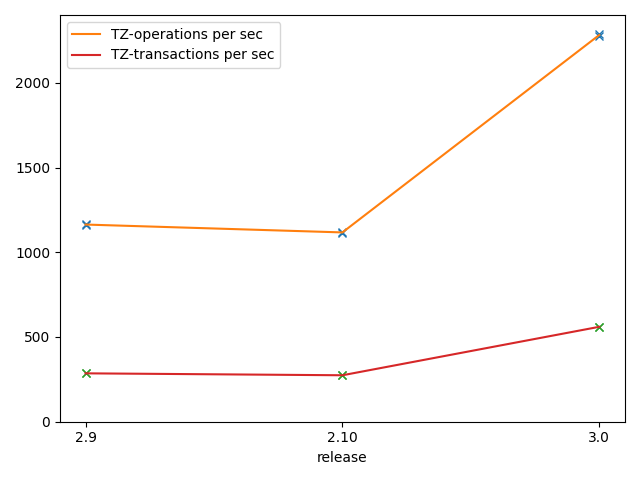
These graphs show a replay of
lib_contextoperations for 1.3 million blocks, on an Equinix c3-small-x86 (1 x Xeon E 2278G 8-Core Processor @ 3.4Ghz), 32G RAM. They measure execution time for CPU, bytes read for read/write operations, and a number of Tezos operations and transactions for Irmin 2.9 and 2.10 (previously released with Octez v11) and Irmin 3.0 (to be released with Octez v13). The bootstrap replay of 1,3 million blocks takes 300min and is validating blocks at ~600 TPS with Irmin 3.0 - available in Octez v13.
Status: This month we released Irmin 3.0, which contains the structured keys feature. It’s in the Tezos master branch with the always indexing strategy for now. In March, we’ll deploy the minimal indexing strategy as well. It will be available in Octez v13.
(Release 3.0.0 by craigfe · Pull Request #1769 · mirage/irmin · GitHub), tezos/tezos#4477.
Integration of Layered Store/GC
The layered store feature consists of organising the context of a Tezos node in two layers: one read-write layer that contains the latest cycles of the blockchain, which can still be reorganised and are not final, and a read-only layer containing older data that’s frozen. The feature initially targets the rolling nodes, which will only keep the read-write layer to save space. Every few cycles, a GC operation will be called to discard the oldest cycles and keep only the more recent ones on disk.
The advantages of a layered store for the rolling nodes is that it uses less disk space and has constant performance throughout the run of a node, without the need to do a snapshot export and import when the disk’s context size gets too big. For archive nodes, the benefit is also better performance while bootstrapping, as only the read-write layer is needed for validating recent blocks.
This month we finished writing a design document for the layered store and implemented an initial prototype. The GC operation must perform a traversal of the oldest block in the live blocks’ window to make sure that all necessary objects are kept in the context. We analysed the expense of this traversal, in terms of runtime and objects visited, for a Hangzhou context. We tested our initial prototype and are currently debugging some issues that occurred during this initial phase of testing.
Status: In March, we plan to benchmark this prototype and start working on a proper integration in Irmin, followed by its integration in Tezos. We envisage it to be part of an Octez release before the end of Q2 this year.
Relevant links: mirage/irmin/2022_layered.
Improve Snapshot Import/Export
Importing and exporting a snapshot from a Tezos node started to consume a lot of memory (up to 8Gb) in Hangzhou because after the context flatenning, the very large directories of a Tezos context (containing a few million entries) were loaded in memory during snapshot import and export. We proposed a temporary fix for importing in December 2021 and worked since then on a proper fix. It consists of exposing the internal nodes used in Irmin to represent these large directories in an optimised way. This allows the node to charge the large directories in memory by chunks, considerably reducing the memory usage. The snapshot’s format changed, but the import will be backwards compatible with older formats. The export, however, will only use this new format.
We have an initial proposition for this which showed promising benchmarks. As this feature comes after Irmin 3.0, more work is needed to properly integrate it with the structured keys feature. We also worked on integrating the import/export operation in our benchmarks, so we can run them every month and ensure there is no regression.
The improvements to the snapshot will be part of an Irmin 3.2 release, expected in March, and should be part of Octez v13.
Status: This work should be available later this year.
Relevant links: mirage/irmin#1757, mirage/irmin#1770.
Record/Replay of the Tezos Bootstrap Trace
A consistent benchmarking process allows for automatisation in the evaluation of the Irmin evolution and provides better quality assurance of Irmin development. Hence, benchmarking Irmin consistently (monthly, at each release, and on each pull request) is a top priority for us, to ensure that no regression is introduced. Our benchmarks consist of recording interaction traces between Irmin and Octez during the bootstrap of a node, which are then replayed for benchmarking and gathering stats. We are working on improving them on several fronts:
- Benchmarking
lib_contextinstead ofirmin, to catch any regression occurring in eitherirminorlib_context. We’ll also maintain the existing Irmin benchmarks for users that want to bench Irmin code directly and for other use-cases. - Starting the benchmark from a snapshot instead of the empty store, as the chain’s performance over the last few months is more informative than its performance has been since the beginning
- Allowing for different parameters, e.g., different
ocamlGC strategies as well as different configuration options for the context - Adding more stats, including
ocamlGC stats and OS stats (e.g., related to page caching)
These benchmarks are very important for Irmin developers, but they’re also important for anyone that contributes to lib_context and for any storage alternative. For instance, it can be used by the Rust implementation of the node tezedge. It’s enough to plug a new storage in lib_context to run these benchmarks.
Status: We have a WIP branch on which we have made a lot of progress. We’re using the improved benchmarks to compare Irmin 3.0 to Irmin 2.10, but this required a bit of extra work when importing the benchmarks to the Irmin 2.10 branch.
Relevant links: Replaying benchmark in irmin.
Publish Irmin/Tezos Performance Benchmarks
We have been running monthly benchmarks for Irmin over the past year. However, we changed the process during this time in order to automate it more. Our goal is to have a year of monthly benchmarks that are all run on the same machine with the same configurations for GC/OS caching and, more importantly, that have reproducible dependencies. For this reason, we’re creating Opam lock files and using opam-monorepo to install them. We are also writing scripts to produce graphs in order to ease readability.
For future monthly benchmarks, we want to automate the process to tag every month’s first day on each benchmarked repo, generate lockfile every month, deploy a bare-metal machine on Equinix (using Equinoxe library), run the benchmarks, and store the result on a backup machine. The results will then be sent to ocurrent-bench GUI to expose them on a public webpage.
Status: This work is a continuous task rolling throughout this year.
Add Merkle Proofs
Optimise Merkle Proofs
Merkle proofs are standardly used to streamline transaction rollups. They efficiently and securely encode blockchain data, meaning users can verify a single transaction without downloading the entire chain. They are used to share partial chain states between parties. For instance, Merkle proofs can be used to implement efficient proxies, light clients (i.e., clients without storage components), or more complex Layer-2 Rollups.
A few months ago, we proposed an initial implementation of Merkle proofs, which was improved by the release of Irmin 2.10.2. We then focused on properly integrating the Merkle proofs in Irmin 3.0. Since this changes the structure of the keys, it has an important impact on how the system implements the proofs.
This month we worked with Nomadic Labs, DaiLamba, and Trilitech on integrating a Merkle proofs API in the Tezos protocol. The hashing schema used in the proof needs to be specified, and two types of hashing schema are allowed: the one used by for the context hash (proof use trees with 32 children) and a binary context (proofs use binary tree), which is optimised for generating smaller proofs.
We plan to write a blog post next month explaining the Merkle proofs API. We also opened a few issues containing improvements to the proofs that can be done in Irmin, such as tests and code refactoring. These are however non-blocking for using the API by Tezos developers.
Status: This is merged into Octez master branch and will be available in Protocol J.
Relevant links: tezos/tezos#4086, tezos/tezos#2418, mirage/irmin#1751, mirage/irmin#1729, tezos/tezos#4307, tezos/tezos#4465.
Provide Support to Tezos
Respond to and Track Issues Reported by Tezos Maintainers
While running Ithacanet, users observed an increase in memory usage. In collaboration with Nomadic Labs, we found that the issue was related to an LRU cache located in Irmin. We benchmarked different LRU sizes to check for cache misses as well as to check the connection between object types and the LRU memory usage. We agreed on decreasing the LRU size by half, which doesn’t negatively impact the node’s performance but improves the memory footprint.
For future work, we plan to change the LRU so that it’s bound by its containing elements’ size instead of by the number of elements, as it is now. This is a safer option because the elements’ size can grow a lot and lead to a memory increase, even if the LRU is bound by number of elements. We plan to work on this improvement in the next few months.
Status: This work is scheduled for Q2 2022.
Relevant links: tezos/tezos#2376.
Improve Tezos Interoperability
Rust and Python Bindings for Irmin
We are working on allowing Tezos users to open an existing data-dir store from applications written in C, Rust, or Python.
The C binding for Irmin is now part of the Irmin repo, and the Python and Rust bindings have been released and are available at mirage/irmin-py and mirage/irmin-rs. As examples, the following code snippets show how to get a commit from the command line and lists all paths containing contents in a Tezos context in Python:
commit_hash = Hash.of_string(repo, sys.argv[2])
commit = Commit.of_hash(repo, commit_hash)
# Open the `master` branch
store = Store(repo, branch=commit)
def list_path(store, path):
"""
Prints all content paths
"""
for k in store.list(path):
p = path.append(k)
if p in store:
print(p)
else:
list_path(store, p)
and similarly in Rust:
// Resolve commit
let hash = Hash::of_string(&repo, &args[2])?;
let commit = Commit::of_hash(&repo, &hash)?.expect("Commit not found");
// Open the store
let store = Store::of_commit(&repo, &commit)?;
fn list_path<T: Contents>(store: &Store<T>, path: Path) -> Result<(), Error> {
for k in store.list(&path)? {
let p = path.append_path(&k)?;
// If the store has contents at `p` then print the path
if store.mem(&p) {
println!("{}", p.to_string()?);
} else {
list_path(store, p)?;
}
Ok(())
}
The scripts are available at mirage/irmin-py/examples/tezos.py and mirage/irmin-rs/examples/tezos.rs.
Status: This work will be available with Octez v13.
Relevant links: mirage/irmin#1713, mirage/irmin-py, mirage/irmin-rs#4
Storage Appliance
An Irmin storage daemon allows for memory reductions in the node usage and for access to remote contexts. This also eases the integration of alternative storage components in Tezos and simplifies the current semantics of storage interactions, so instead of every process linking the Irmin runtime (and potentially maintaining distinct caches in memory), only one process (the daemon) is used for all interactions with the Irmin context. It also simplifies the semantics of interactions between read-write and read-only instances, as we don’t have to use the filesystem as an inefficient inter-process communication mechanism.
The server can also be used to access a context that is remote, e.g., in the case where not enough storage is available locally.
The implementation for irmin-server is well tested, and our next work consists in integrating a storage alternative in Tezos. We started working on a branch of Tezos that integrates the irmin-server. Our strategy is to add irmin-server/client as backend in Irmin. This requires minimal changes to the Tezos code to integrate the Irmin daemon while also making the backend available to other Irmin users. To figure out the difficulty of this, we plan to first try the irmin-http backend in Tezos. We refactored the code to remove a dependency on Unix, and we’re working towards abstracting the I/O. A dependency in Tezos needs this.
Status: As this isn’t a high priority, the integration in Tezos will be ready for users to try later this year.
Relevant links: mirage/irmin-server#29.
Maintain Tezos’s MirageOS Dependencies
General Irmin Maintenance
All the maintenance work aims to permanently improve the quality of the code and speed up the implementation of future new features.
Backend maintenance was necessary due to the Irmin 3.0 changes. For instance, the changes in Irmin 3.0 affected backends other than irmin-pack. We fixed the GraphQL and the irmin-git backend. We’re also reworking the GraphQL test suite.
Moreover, parts of Octez are now getting usable inside browsers.
In collaboration with Nomadic Labs, we ported irmin-pack.mem to compile with js_of_ocaml to make parts of Octez usable inside browsers. This required splitting the Unix-specific part out of irmin-pack, and we released Irmin 3.1 with this change.
Status: Rolling.
Relevant links: mirage/irmin#1783.


