Increasing the speed at which blocks are applied is one of the most effective methods of improving a blockchain node. When new blocks are applied, the blockchain’s protocol reads from and writes into the node’s storage, which stores the blockchain state (which is known as the context in Tezos).
To improve the performance of the node, we want to make this process as fast as possible. While the TezEdge context storage implementation offered decent performance, we knew there was some unnecessary latency and overhead when the protocol interacted with it.
These latencies came from the use of an inter-process-communication (IPC) mechanism to handle the communication between the protocol and the TezEdge context storage. To solve this, we decided to implement, with the help of our ocaml-interop library, a new communication layer between the protocol and the context storage that instead uses direct function calls. In doing so we got rid of the latency overhead and also enabled the possibility for many new optimizations that we will describe in this article.
The optimizations involved significantly reducing the amount of memory allocations, a much more compact in-memory representation of the context storage, reduced locking and faster data serialization.
As part of these improvements, we also introduced better speed measurements that now better reflect how much time is spent by the protocol when accessing the context storage, along with visualizations in our TezEdge Explorer tool to clearly see where time is being spent.
The structure of the context Merkle tree
In Tezos, the blockchain state (called the context) is stored in the form of a Merkle tree, which is a type of data structure that utilizes hash functions to create a tree-like system of referencing.
In our past article on how the Tezos context is stored in the form of a Merkle tree, we used the terms “Commit”, “Tree” and “Blob”,for the various types of objects that constitute a Merkle tree. Here, we use the term Directory instead of Tree and Value instead of Blob, but otherwise, the concept remains the same.

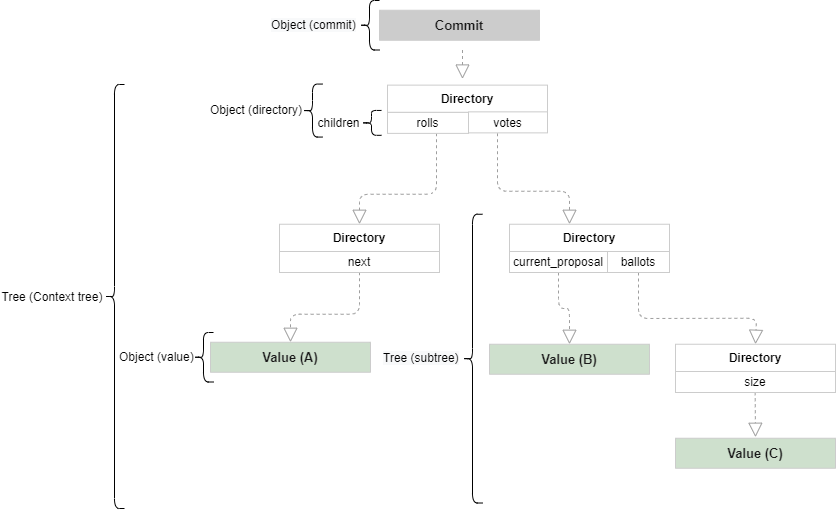
The context tree is a Merkle tree that represents the context (the blockchain state). It is composed of two kinds of objects:
- Directories — do not contain data in themselves, but they may contain references to values that do contain data, or references to other directories that contain values. They are the ‘branches’ of the context tree.
- Values — A sequence of bytes. They do not refer to other Values and Directories. Values are the ‘leaves’ of the context tree.
Additionally, a commit is a tag with date and time that points to the root of the context tree. While it points to the context tree, it is not a part of the tree itself.
Please note that we use the term tree only when referring to a collection of one or more directories and values, while directory and value are just single objects within a tree.
The context (blockchain state) is versioned, and whenever it is modified and saved, the old version is still available. Versions of the context tree (the Merkle tree that represents the entire context) are stored in the repository, a data store to which we can save objects, and retrieve them by their hash.
Each version of the context tree is identified by the hash of its commit.
The blockchain contains a sequence of blocks. Blocks are composed of a collection of operations to be performed (for example, transferring ꜩ from one account to another). The application (processing) of a block involves:
- Loading an initial state. This is done by reconstructing (from the repository) the version of the context tree specified by the block. This is called a checkout, and the resulting context tree is known as the working tree.
- Apply each operation to transform the working tree and produce a new version. This is done through a specific set of queries that read and manipulate the working tree.
- The working tree is then committed (saved) to the repository.
To commit a context tree, it must first be serialized (translated into a format that is easier to store) and hashed. A context tree is serialized by decomposing it into the objects constituting it (directories, values, commits), which then get serialized. All serialized objects are then saved to the repository and associated with their hash. Finally, a commit object is produced, hashed, and saved too. This commit object will serve as a marker for this version of the context tree.
There are some aspects that are important for performance:
- Fast modification of the working tree
- Fast reconstruction of the working tree from the repository
- Fast saving of the working tree to the repository
- Efficient use of the system memory (less memory usage)
Integrating the context storage with the Tezos protocol
The Tezos economic protocol is a set of rules that determine how the ledger is updated, what constitutes a valid block and operation, the structure of the context (blockchain state), and other aspects of the Tezos blockchain. The code that implements the economic protocol doesn’t know anything about how the context storage is implemented, only that it implements a specific application programming interface (API). Any implementation of the context storage (the part of the node that stores the blockchain state) must implement an API that is compatible with the protocol in order to function properly.
This means that it is possible to switch context storage implementations and the protocol will work well with them as long as they implement the right API.
We introduced two new modules that implement this API. The first one takes care of connecting the protocol to the TezEdge context. It was implemented with the help of our ocaml-interop library, which allowed us to integrate our context storage and the Tezos economic protocol more tightly together and have them safely share the same memory space.
This also allows us to almost seamlessly share values between Rust and OCaml without having to copy them from one language to the other. What used to require communication between processes is now done through direct function calls between Rust and OCaml code. This considerably improves the performance of the working tree by removing latencies and avoiding data copying.
The other module is an overlay over both the TezEdge and Irmin contexts. This allows us to run the node with either Irmin or TezEdge as the context storage implementation, or both at the same time. It also has the option to measure and record the time it takes to query the context.
The remaining optimizations involve improvements to the in-memory representation of the working tree, the repository, and improvements to the serialization of the context state tree.
Old implementation
The original implementation of the repository used a hash table, a type of key-value store that, in our case, maps the keys to objects and makes them addressable by their hashes. Every time the working tree was committed at the end of the application of a block, each object in the tree, as well as the commit object, were hashed, serialized, and added to this hash table. Directories were also represented using hash tables (with names as keys and child object hashes as values).
The implementation was straightforward and very close to the abstract description of a Merkle tree. Its shortcoming was that it did not use memory efficiently. Let’s first go over the sources of overhead before we describe the optimizations.
Sources of overhead
Hashes: each hash has a size of 32 bytes. For a few hashes, this is not a big deal, but if we store the hash of every object (directory, value, or commit) in the store, that ends up adding to a lot of hashes. If we take into account that most values in the context tree are also small (just a few bytes), we end up spending more space to keep hashes around than to store the actual values. In addition, because hashes were stored with their data embedded in directories, the same hash would end duplicated multiple times (once in the repository, at least once inside a directory containing the child object, and once again in the structures used by the context garbage collector for bookkeeping purposes).
Arc/Rc overhead: Rust provides two data wrappers that add reference counting to a value, Rc (single-threaded) and Arc (multi-threaded). In a serialized context tree, serialized objects are just a sequence of bytes, but in the original representation, every single value was wrapped in Arc<[u8]> (a sequence of bytes wrapped in a reference-counted container that can be shared between threads). The Arc wrapper is needed because the main thread and the garbage collector thread need to share the same value. The reason is that the garbage collector inspects directories to be able to find references to other objects. This results in quite a bit of overhead, especially for small values. We will get back to this later in the article.
For example, when we have 186,725,376 instances of Arc, each of those instances has 16 bytes overhead, this results in 2.98 GB memory used only for the Arc counters.
Hash tables: when using a hash table to represent the repository and directories, along with the strings and object hashes that we use as keys (and end up duplicated again because hash tables need to keep a copy of the key), we also need to keep another 8 bytes hash, which is the hash of the key, that the hash table uses to search for the associated values.
Allocations: with each object being stored on its own, one memory allocation is needed for every object, and then a deallocation is needed when the object isn’t used anymore. This can lead to memory fragmentation, and as a consequence, slower access and wasted memory. This is an issue especially when manipulating the working tree, because a lot of new values are created and discarded until it is committed.
Serialization: at the end of the application of a block, when the working tree is going to get committed, the tree needs to be serialized before it gets saved to the repository. In the old implementation, serialization of values was done with bincode (a popular encoder for serialized data). However, it turns out that for the kind of values we store (as well as because bincode is generic), it cannot assume much about the data, and misses important opportunities to produce a more compact representation faster.
Locks: data was shared between the main thread and the thread that performs the garbage collection. This required locking that could introduce some latency while the garbage collector was doing its work at the end of a cycle (a sequence of blocks that are used as a unit of time in the Tezos blockchain).
Deduplication and flat representation
The first optimization involves the deduplication of object hashes and the strings that compose the fragments of a path (in the path “a/b/c”, “a”, “b” and “c” are fragments) in the context tree. The goal is to reduce the amount of redundant copies, and also the amount of allocations.
This was achieved by adding an extra level of indirection to be able to replace instances of these values with a single 4 bytes identifier. Additionally, they are now all stored together in preallocated contiguous blocks of memory. This applies to all the objects in our context tree.
Hashes are now stored inside a single preallocated vector, with each slot having the amount of space required by one hash. When a new hash is created, it is stored in a free slot in this vector (no allocation needed), and we get back a unique 4 bytes ID (HashId) to use elsewhere in place of the 32 bytes hash. Now, each time this hash shows up anywhere in the tree, we only need 4 bytes (instead of 32) to represent it. When the garbage collector runs, hashes that are not needed anymore are discarded and the space is reclaimed to be used by future hashes.
Strings that represent path fragments, when small, are now all stored concatenated into a single preallocated big string, and represented as a “StringId”, a 4 bytes integer that contains the position of this substring in the big string, and its length.
This representation is more compact, and avoids duplication, allocations and overhead (before we either duplicated these strings all the time, or wrapped them in an Rc which incurred the same overhead shown above for small values).
For example, if we have 2 strings “hello” and “abc”, we store them in a single string: “helloabc”. We access those 2 strings with 2 different “StringId”, but they are stored in the same memory space, and 1 allocation was needed instead of 2. When the string is big (its length is superior or equal to 30 bytes), a different StringId is used.
This adds an additional indirection where the offsets of such strings are stored in another structures (indexes in the diagram)
For example: Let’s say that a big string (>= 30 bytes) has a StringId of 2. This 2 is the index inside the vector indexes. We check the values of indexes at the index 2, we found that start and end are 70 and 110.To be able to find this string, we read the big strings from the index 70 until 110.
Directories in the context tree are now all concatenated in a single big vector. We were previously using a hash table to represent a directory. While correct, this structure used more memory than necessary.
We also need only a few functions on directories: search, find, insert and remove. The context now has DirectoryId, which is a reference to a sublice inside the big vector.
Using a vector-based storage significantly reduced the number of allocations made (we allocate only to grow the vector, instead of allocating each individual object) and the result is a faster block application, and less RAM used. A full bootstrap used to take 3 days and now takes approximately 2.
Flattening of the working tree
We observed that one of the performance bottlenecks of the context in the TezEdge node is related to the number of allocations made. When the protocol applies a block, a lot of temporary objects get created when modifying (writing into) the working tree.
This leads to several inconveniences:
1. Allocator-specific reliance
It makes the performance of our context rely on the allocator implementation: a slow allocator leads to a slow modification of our context. Rust allows the changing of the global allocator to a custom one, or jemalloc for example, but that wouldn’t address the additional two issues that are described below.
2. Memory fragmentation
When the CPU accesses our object from memory, it first checks if this object is in the data cache (the data cache is like the RAM, but smaller and faster). If the object is not in the cache, it is called a cache miss, in that case the CPU needs to load the object from the RAM into the cache. Because all our objects are in different places in the memory (RAM), the CPU has to do the expensive process of loading it into the cache first.
3. Memory overhead
The aforementioned objects are shared in different parts of the code, so they are allocated with smart pointers (or shared pointers). Smart pointers have the benefit of being deallocated when all references are dropped to avoid memory leaks, but they also have a lot of memory overhead:
Rust smart pointers (Rc and Arc) are reference counted pointers, meaning that for each pointer, there are 2 extra counters: a strong counter and a weak pointer. This means that when we allocate an object, it allocates the size of the object + 16 bytes for the counters.
In addition, Rust allows us to have shared pointers to a slice of memory (Rc<[u8]>), this pointer has 8 extra bytes to store the length of the slice, making a total of 24 extra bytes.
Inside the Tezos context, most values are small, so this overhead ends up being quite big. Consider, for example, how much extra space is needed for a 4 bytes value.
The Rc/Arc wrapping will add an extra 16 bytes (a strong counter and a weak counter, 8 bytes each). Then the pointers to these values cost 16 extra bytes (8 for the pointer address, and 8 for the size of the slice).
To solve those issues, we decided to use a centralized system where all objects of the same type are allocated in an array, then indexed by an 8 bytes identifier.
Thus, when creating and using an object, the user of that system identifies the object by an index, as it doesn’t have any pointer anymore. Instead of requesting more memory to the allocator (and eventually to the OS), creating an object uses only a free slot in the (already allocated) array.
Using such a system addresses the 3 issues we described above:
1. We do not make use of the allocator anymore. We only use it when we need to grow the array, but that happens far less often than before for each individual object.
2. The objects are next to each other, so that when the CPU wants to access an object, it will load it in the data cache. If the CPU wants to access the next object, it is already in the data cache, so it doesn’t need to load another part of the RAM into the cache.
3. We are getting rid of the smart pointers counters: this is saving 16 or 24 bytes for each object. Because the lifetime of our objects won’t last longer than after the block application, we can deallocate our objects all at once when a new block starts being applied.
An array index need fewer bits than a pointer (64 on 64 bits architecture), this also allows us to have a smaller data structure containing those indexes, which means we have a better usage of the cache.
For example: our StringId is 32 bits, if we used a pointer, the pointer itself would be 64 bits.
We are now applying blocks faster, with a smaller memory footprint, using 100% safe Rust.
Serialization
When the working tree gets committed, all objects in the tree are hashed and serialized. Since the old implementation represented directories using a hash table, and was serialized with bincode, the resulting serialized value used far more memory than necessary. For example, a small directory of 2 children “a” and “b” required about 100 bytes.
With the new more compact representation described above, and the implementation of a custom serializer, now the same directory can be serialized in just 11 bytes.
We are using the following encoding to serialize our different objects:
Directory:


- The first byte is a tag that identifies that this object is a directory
- Then all children objects use a single byte with a descriptor (described below), N bytes for the name of the child object, and 4 bytes for the HashID that references the child object (there is an exception for inlined values, which will be described in the next section).
Descriptor above is 1 byte, defined as follow:


- The “kind” bit defines if the object is a leaf or not (a directory or a value).
- The 3 bits for the “inlined value length” define the size of the value if it is inlined (see next section), unless the length is 0, in that case the value is not inlined and is instead referenced by a HashID.
- The last 4 bits are used to define the key length. If the key length doesn’t fit in 4 bits, then an additional 2 bytes are added after “descriptor” to specify the key length.
Value:


- First byte is a tag that identifies that this object is a value
- The remaining bytes are the data of this value. There is no field specifying the length of the data field, but we know how long it is because these bytes are stored in a vector, so we just subtract 1 byte from it, and the result is the length of the data.
Commit:


- First byte is a tag that identifies that this object is a commit
- The next 4 bytes are the HashID that references the root of this commit’s tree
- The next 4 bytes are the HashID that references the parent commit
- The next 8 bytes are the timestamp of this commit
- Then for the author and message of the commit, we have for each 4 bytes with the length, followed by N bytes with the data
Inlining of small values
Serializing a directory means that we have to keep a hash for each child object. We realized that most of the serialized values are less than 8 bytes in size. Therefore keeping a hash (32 bytes) for each small value (less than 8 bytes) brought unnecessary memory overhead.
So instead of serializing those small values and storing their hash, we decided to store the value directly in its parent directory.
A serialized directory with 2 children, “name” and “other”, takes the following form in memory:


The hash ID allows the retrieval of the object from the repository by its hash.
The “Descriptor” is a single byte that provides some details about the child, as described in the section above.
By inlining the small values, we have the following in memory. For instance, let’s assume that “name” points to the value “abcdef”. If that value gets inlined, the serialized directory now looks like this:


While the serialized directory now consumes more memory (22 bytes vs 20 bytes), we no longer store the object hash which is 32 bytes, and also avoid the 4 bytes for the HashID. That means that we saved 34 bytes in this example.
The downside is that we have to recompute the hash of the small values on every commit. However, this is a good tradeoff considering the amount of memory space that we saved. Also, hashing such small values is relatively fast.
To give a number, on the block level 1530711, 430 millions inlined values were serialized since block 1.Inlining values during serialization saved about 15.5GB (430M * (32 bytes + 4)) of memory (due to not keeping the hash and its hash ID).
There is another advantage of this representation: for the upcoming persistent implementation of the context, fetching directories from the repository will already include some (or all) of its children values, saving I/O roundtrips.
Measuring the storage’s performance
When working on these optimizations, we made use of some of the new features in our front end — the TezEdge Explorer. In the intermediary context module, we measure the time it takes to execute each context action (for both Irmin and TezEdge contexts). We can now find this data in the front end:
http://storage.dev.tezedge.com/#/storage
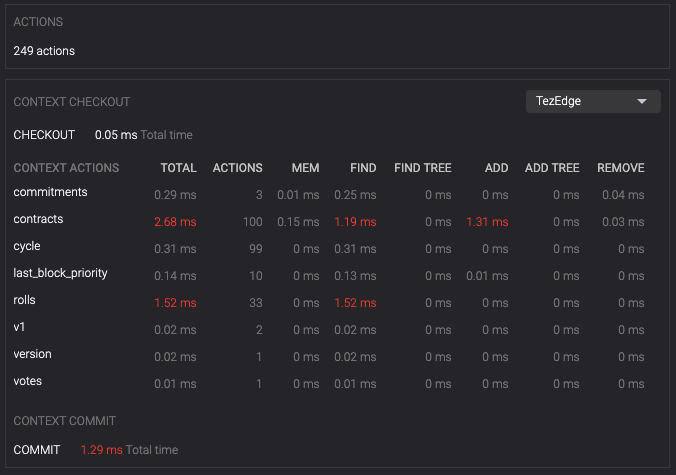
Horizontal rows display information about the datetime, level, cycle and hash of a specific block. Hovering the cursor over a specific row selects that block and displays how much time each context action took. When we hover above a directory (for example rolls), we can see how many Actions were performed, the Total Time they took to be processed, the Mean (average) time and the Max (maximum) amount of time an action in that directory took.

http://storage.dev.tezedge.com/#/resources/storage
On this screen, we can see the global stats for the action types commit and checkout.

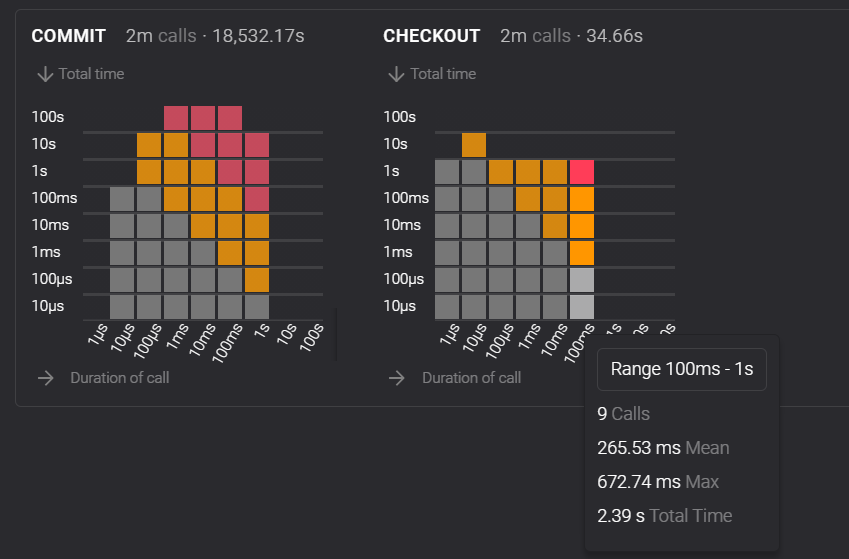
Hovering the cursor over a column displays calls categorized by the time they took, for instance, this screenshot displays the category of CHECKOUT calls that took between 100ms to 1s. Again we can see how many Calls were performed, the Mean (average) time and the Max (maximum) and the Total Time they took to be processed.
The measurements are taken for both Irmin (the OCaml Tezos node’s context storage) and the TezEdge node’s context storage.
With this we can obtain insights about where most of the time is being spent when executing context operations to inform our future decisions about what to optimize. For example, in the first screenshot, it can be seen that most of the time is being spent in the contracts and rolls directories.
Because we record every action, we can also find out about data access patterns, which can provide useful information we could use to help with the implementation of a cache or a data prefetching mechanism.
The improved integration of the TezEdge context storage with the Tezos economic protocol has reduced overhead, but it has also opened the door to even further optimization, such as avoiding memory allocations as we can now read data directly from the OCaml heap. Our efforts in this area will be well-informed by the measurements of the storage context which you can yourself see via the in-browser TezEdge Explorer UI.
Last, but not least, the integration of the context storage with the economic protocol provides the foundations to use TezEdge’s context storage directly from the OCaml Tezos node, though this will require further development down the line.
How to test the optimizations
- First, you need to clone this repo.
git clone https://github.com/tezedge/tezedge.git
- Then change into the cloned directory
cd tezedge
- Run docker by typing these commands:
a) To test with Irmin:
docker-compose -f docker-compose.storage.irmin.yml pulldocker-compose -f docker-compose.storage.irmin.yml up
And visit http://localhost:8282 in your browser.
b) To test with TezEdge’s in-memory context storage:
docker-compose -f docker-compose.storage.memory.yml pulldocker-compose -f docker-compose.storage.memory.yml up
And visit http://localhost:8181 in your browser.
We hope you have enjoyed our update article. Feel free to contact me by email, I look forward to receiving your questions, comments and suggestions. To read more about Tezos and the TezEdge node, please visit our documentation, subscribe to our Medium, follow us on Twitter or visit our GitHub.


